BUD-E: ENHANCING AI VOICE ASSISTANTS’ CONVERSATIONAL QUALITY, NATURALNESS AND EMPATHY
by: LAION, 08 Feb, 2024
AI voice assistants have revolutionized our interaction with technology, answering queries, performing tasks, and making life easier. However, the stilted, mechanical nature of their responses is a barrier to truly immersive conversational experiences. Unlike human conversation partners, they often struggle with fully understanding and adapting to the nuanced, emotional, and contextually rich nature of human dialogue, leading to noticeable latencies and a disjointed conversational flow. Consequently, users often experience unsatisfactory exchanges, lacking emotional resonance and context familiarity.

Wouldn’t it be awesome to have a fully open voice assistant that can
- reply to user requests in real-time
- with natural voices, empathy & emotional intelligence
- with long-term context of previous conversations
- handling multi-speaker conversations with interruptions, affirmations and thinking pauses
- fully local, on consumer hardware.
To realize this vision, LAION teamed up with the ELLIS Institute Tübingen, Collabora and the Tübingen AI Center to build BUD-E (Buddy for Understanding and Digital Empathy).
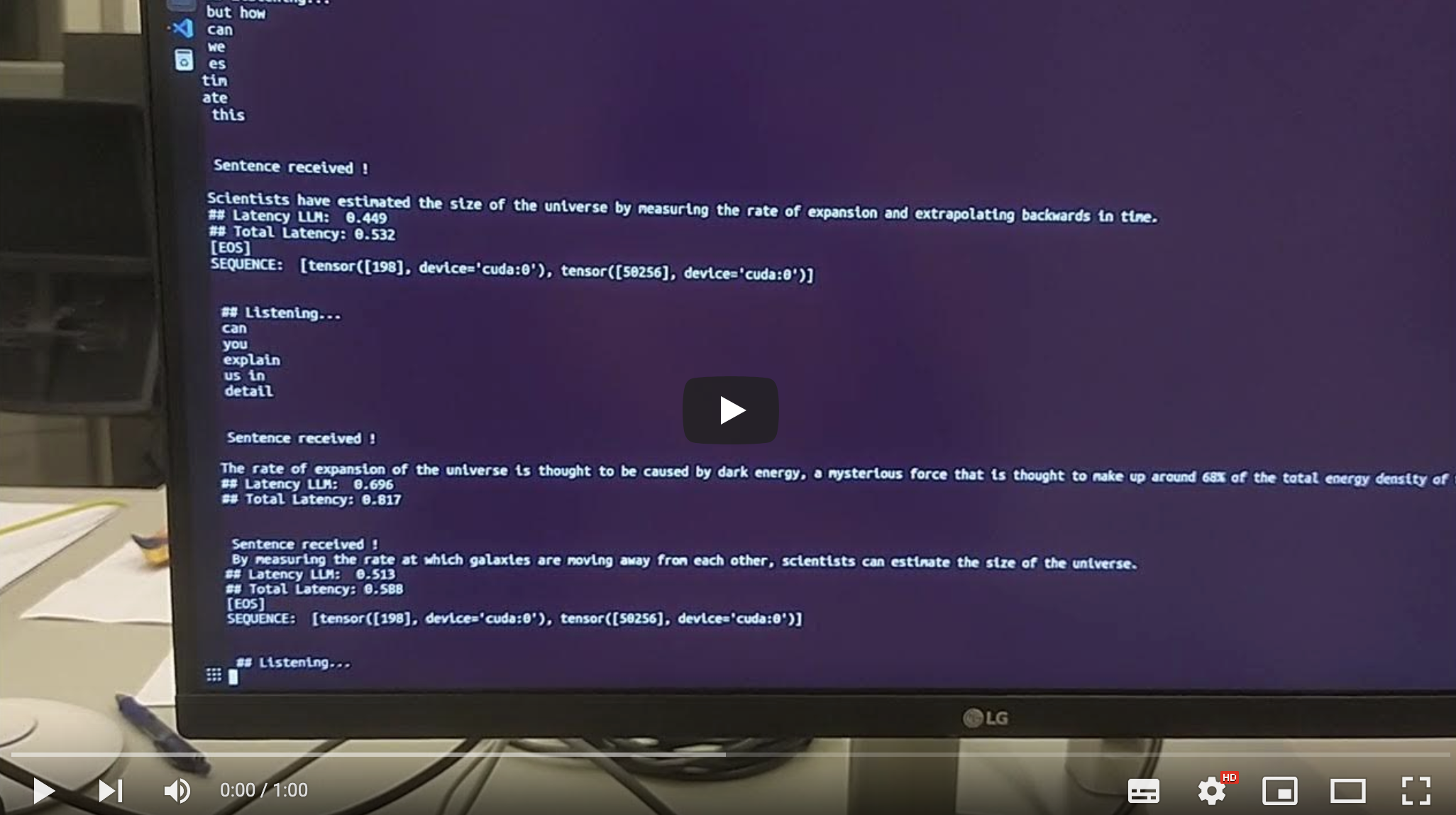
We started the development by creating a baseline voice assistant with very low latency. To reach that point, we carefully evaluated latency and quality of a large range of Speech-to-Text, Large Language and Text-to-Speech models on consumer hardware and carefully control how the models interact. Right now (January 2024) we reach latencies of 300 to 500 ms (with a Phi 2 model). We are confident that response times below 300 ms are possible even with larger models like LLama 2 30B in the near future.
Here is a demo (running on a 4090 GPU): BUD-E Demo
All code is open-source and available at GitHub.
A roadmap towards Empathic & Natural AI Voice Assistants
Conversations even with the baseline model feel much more natural than anything we’ve seen so far. Nonetheless, there are still a lot of components and features missing that we need to tackle on the way to a truly empathic and naturally feeling voice assistant that is fun and helpful to interact with over prolonged periods of time. We are inviting everyone to contribute to the development of BUD-E.
The immediate problems and open work packages we’d like to tackle are as follows:
Reducing Latency & minimizing systems requirements
- Quantization: Implement more sophisticated quantization techniques to reduce VRAM requirements and reduce latency. Fine-tuning streaming TTS. TTS systems normally consume full sentences to have enough context for responses. To enable high-quality low-latency streaming we give the TTS context from hidden layers of the LLM and then fine-tune the streaming model on a high-quality teacher.
- Fine-tuning streaming STT: Connect hidden layers from STT and LLM system and then fine-tune on voice tasks to maximize accuracy in low-latency configurations of STT model.
- End-of-Speech detection: Train and implement a light-weight end-of-speech detection model.
- Implement Speculative Decoding: Implement speculative decoding to increase inference speed in particular for the STT and LLM models.
Increasing Naturalness of Speech and Responses
- Dataset of natural human dialogues: Build a dataset (e.g., Youtube, Mediathek, etc.) with recorded dialogues between two or more humans for fine-tuning BUD-E.
- Reliable speaker-diarization: Develop a reliable speaker-diarization system that can separate speakers, including utterances and affirmationsthat might overlap between speakers.
- Fine-tune on dialogues: Finetune STT → LLM → TTS pipeline on natural human dialogues to allow the model to respond similarly to humans, including interruptions and utterances.
Keeping track of conversations over days, months and years
- Retrieval Augmented Generation (RAG): Implement RAG to extend knowledge of BUD-E, unlocking strong performance gains
- Conversation Memory: Enable model to save information from previous conversations in vector database to keep track of previous conversations.
Enhancing functionality and ability of voice assistant
- Tool use: Implement tool use into LLM and the framework, e.g., to allow the agent to perform internet searches
Enhancing multi-modal and emotional context understanding
- Incorporate visual input: Use a light-weight but effective vision encoder (e.g., CLIP or a Captioning Model) to incorporate static image and/or video input.
- Continuous vision-audio responses: Similar to the (not genuine) Gemini demo it would be great if BUD-E would naturally and continuously take into account audio and vision inputs and flexibly respond in a natural manner just like humans.
- Evaluate user emotions: Capture webcam images from the user to determine the user’s emotional state and incorporate this in the response. This could be an extension of training on dialogues from video platforms, using training samples where the speaker’s face is well visible.
Building a UI, CI and easy packaging infrastructure
- LLamaFile: Allow easy cross-platform installation and deployment through a single-file distribution mechanism like Mozilla’s LLamaFile.
- Animated Avatar: Add a speaking and naturally articulating avatar similar to Meta’s Audio2Photoreal but using simpler avatars using 3DGS-Avatar.
- User Interface: Capture the conversation in writing in a chat-based interface and ideally include ways to capture user feedback. Minimize Dependencies. Minimize the amount of third-party dependencies.
- Cross-Platform Support: Enable usage on Linux, MacOS and Windows. Continuous Integration. Build continuous integration pipeline with cross-platform speed tests and standardized testing scenarios to track development progress.
Extending to multi-language and multi-speaker
- Extend streaming STT to more languages: Extending to more languages, including low-resource ones, would be crucial.
- Multi-speaker: The baseline currently expects only a single speaker, which should be extended towards multi-speaker environments and consistent re-identification of speakers.
Collaborating to Build the Future of Conversational AI
The development of BUD-E is an ongoing process that requires the collective effort of a diverse community. We invite open-source developers, researchers, and enthusiasts to join us in refining BUD-E's individual modules and contributing to its growth. Together, we can create an AI voice assistants that engage with us in natural, intuitive, and empathetic conversations.
If you're interested in contributing to this project, join our Discord community or reach out to us at bud-e@laion.ai.