TRAINING CONTRASTIVE CAPTIONERS
by: Giovanni Puccetti, Maciej Kilian, Romain Beaumont, 02 Feb, 2023
We introduce a new model type to OpenClip Contrastive Captioners (CoCa) [1]. This model adds an autoregressive objective (generation) on top of the CLIP contrastive one. The architecture is composed of three parts, the first two are similar to those composing a CLIP model and the third is a text decoder that stands on top of the text encoder. The additional decoder takes as input the encoded images (through cross-attention) and the previous tokens to predict the next most probable one. One of the few architecture changes, compared to CLIP, is attentional pooling [2], used to aggregate image representations and pass them to both the contrastive loss and the decoder cross-attention.
This is interesting for several reasons:
- We believe there is no openly available trained model with this architecture;
- Adding a generative task appears to help the contrastive task with minimal computational impact;
- The model is easily adaptable to a large number of tasks, on top of all those CLIP is suited for. CoCa models can (with relatively cheap fine-tuning) perform Image Captioning, Visual Question Answering, Multimodal Understanding, and more;
- CoCa gives captioning models an intermediate contrastive latent space for minimal training cost increase.
Benchmarks
On a comparable model size and with the same training data available, CoCa outperforms a CLIP model on several zero-shot tasks (Figure 1). Most notably on imagenet1k CoCa achieves 75.5 and CLIP 73.1 (2.6% improvement).
(a) 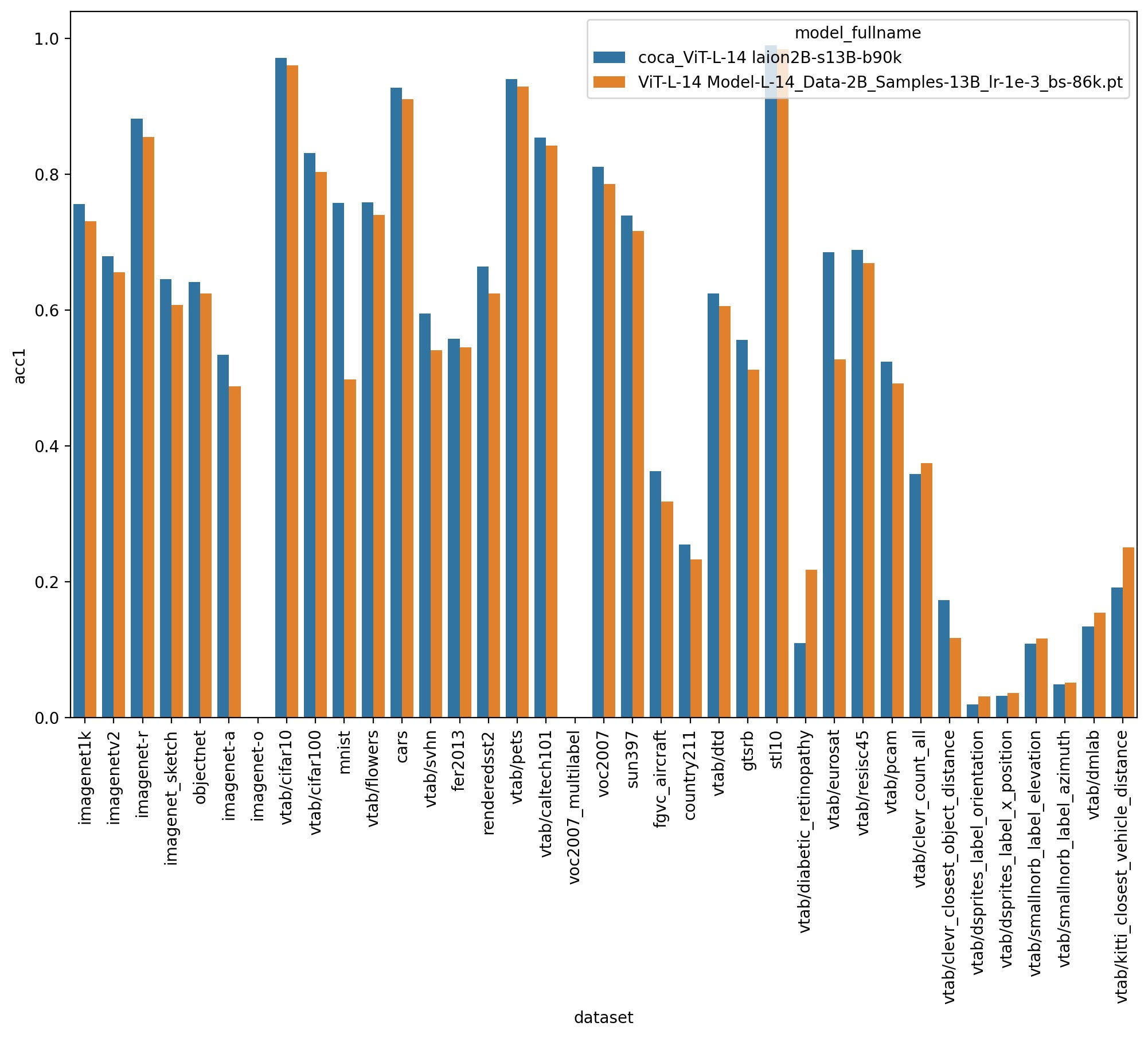 |
(b) 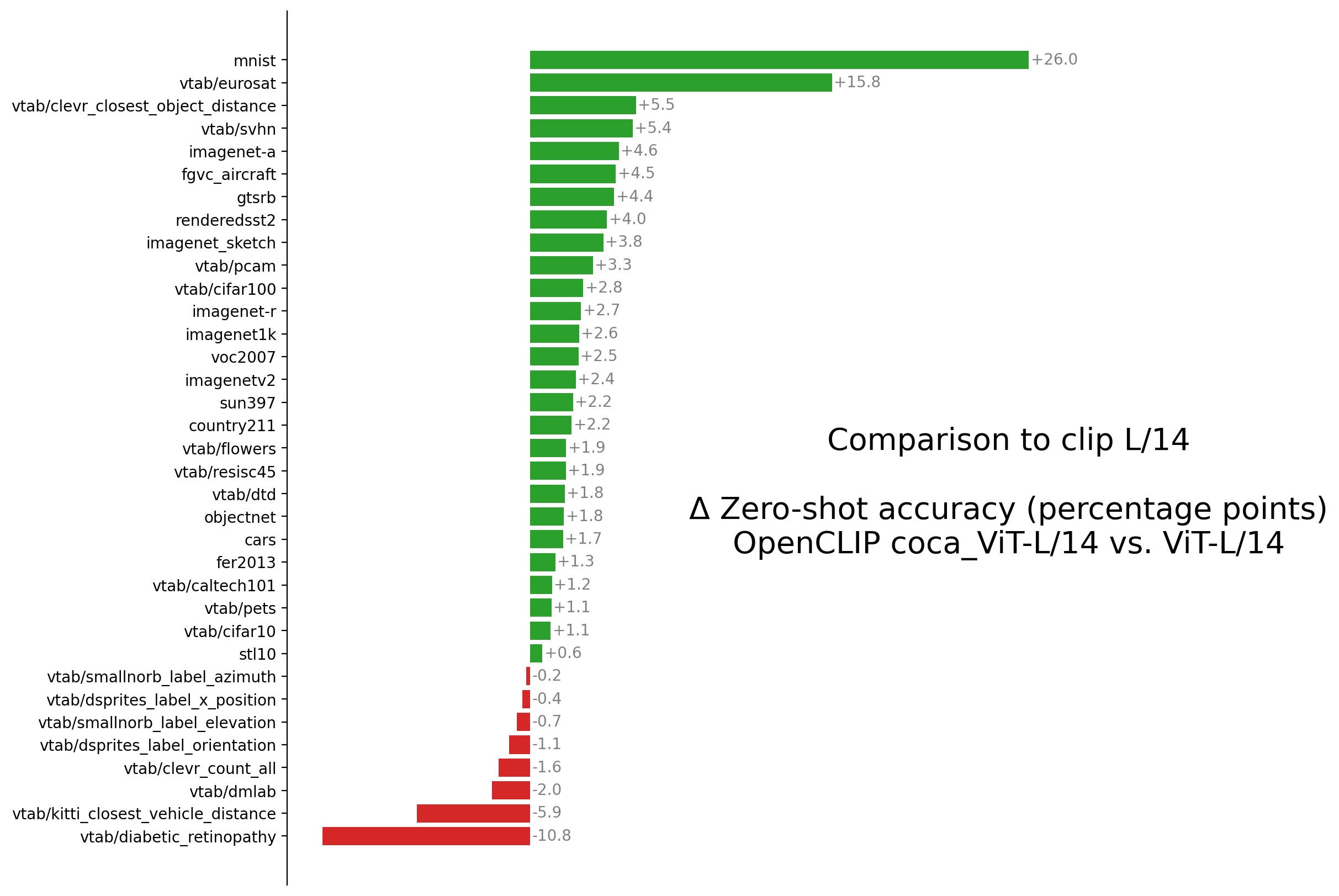 |
|---|
Figure 1: Scores achieved by coca_ViT-L-14 and ViT-L-14 on several zeroshot classification tasks (a), together with the performance gap between the two models, in the same tasks sorted by magnitude (b).
Table 2 shows the results achieved on Text to Image and Image to Text retrieval by both CoCa and CLIP. In this case too, CoCa outperforms CLIP on all tasks with differences ranging from 0.3 to 1.3.
| Text to Image Retrieval Recall@5 | |||
| flickr30k | flickr8k | Mscoco captions | |
| coca_ViT-L-14 | 92.0 | 70.1 | 70.5 |
| ViT-L-14 | 91.7 | 69.0 | 69.2 |
| Image to Text Retrieval Recall@5 | |||
| flickr30k | flickr8k | Mscoco captions | |
| coca_ViT-L-14 | 99.3 | 81.7 | 83.6 |
| ViT-L-14 | 98.4 | 81.2 | 83.0 |
Table 2: Text to Image and Image to Text retrieval Recall@5 on flickr30k, flickr8k and Mscoco captions.
Released Checkpoint
We release checkpoints for two model configs, coca_ViT-B-32 and coca_ViT-L-14. We also release the MSCOCO finetunes of those models which are much better at captioning but unfortunately lose their contrastive capabilities during fine tuning.
Try generation in this Space or in this colab notebook!
| L/14 | B/32 | CoCa (from paper) | |
| # Params Image Encoder | 306.72M | 89.16M | 1B |
| # Params Text Encoder | 123.65M | 63.42M | 1.1B |
| # Params Text Decoder | 208.07M | 100.96M |
Table 3: Number of parameters for each encoder/decoder component for coca_ViT-L-14, coca_ViT-B-32 and the CoCa model from the original paper (M=millions, B=billions).
Training Notes
Pretraining
We train both model configurations on 13B samples seen from LAION-2B [3] with a batch size of 90k, learning rate of 1e-3, and a cosine decay learning rate schedule. Experiments were performed on 384 A100’s and over the course of training we maintained 75.5 samples/s/gpu (~29k samples/s in total).
When it comes to cost, even though CoCa has more capabilities than single-task captioning models there’s a minimal increase ~20% (as reported by Table 8b of the paper). This is due to the fact that the first half of the text decoder (i.e. the text encoder) is unimodal and is computed in parallel to the image encoder, once the encoders are done we simply continue the forward pass of the text embeddings through the text decoder and also include the image embeddings via cross attention. The trainig report can be found here.
Fine-tuning
For image captioning tasks fine-tuning is a straightforward extension of pretraining with few hyper parameters changes. The crucial one is contrastive loss weight, which has to be set to zero to let the backward pass only account for the generative loss, besides there are no additional fine-tuning oriented components nor changes in the loss. We use a batch size of 128 with a learning rate of 1e-5 and a cosine learning rate schedule. Experiments are performed on 4 A100's. Table 4 shows the language generation scores achieved by coca_ViT-L-14 and by CoCa in the original paper, _coca_ViT-L-14 performance is still far from the original CoCa model one.
It is noteworthy that (in our experiments) after fine-tuning with a generative only loss these models lose their contrastive skills entirely.
| Bleu@4 | METEOR | CIDEr | Spice | |
| coca_ViT-L-14 | ||||
| Karpathy val | 35.6 | 29.8 | 125.3 | 23.4 |
| NoCaps | 39.9 | 29.1 | 106.5 | 14.7 |
| Original CoCa (from paper) | ||||
| Karpathy val | 40.9 | 33.9 | 143.6 | 24.7 |
| NoCaps | - | - | 122.4 | 15.5 |
Table 4: Visual captioning scores achieved with coca_ViT-L-14 on karpathy validation set and NoCaps.
Captioning Examples
 |
 |
|---|---|
| An apple sitting on top of a wooden table. | A painting of a raccoon in a space suit. |
What’s Next
- Unimodal Text Pretraining - One of the shortcomings of CoCa is that it can have trouble with zero-shot captioning because the noisy web text it was trained on isn’t as rich as unimodal text data. To this end we can look into methods that provide CoCa models with this rich text understanding either via initializing the weights of the decoder with some pretrained unimodal text decoder or perhaps alternating between multimodal and unimodal losses that use different data.
- Fine tuning on more tasks VQA, multimodal reasoning, and more.
- Image Decoder - CoCa adds a multimodal text decoder on top of CLIP and shows this multi-task learning can benefit both tasks. Why not also add a multimodal image decoder?
Contributions and acknowledgements
Thanks to
- gpucce and iejMac for implementation into open_clip and training the models.
- lucidrains for initial implementation.
- Romain Beaumont and Ross Wightman for advice, reviews, and engineering support.
- Soonhwan-Kwon for implementing beam search.
Huge thanks to Emad and StabilityAI for providing the compute resources required to train these models.
References
[1] Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., & Wu, Y. (2022). CoCa: Contrastive Captioners are Image-Text Foundation Models. ArXiv, abs/2205.01917.
[2] Lee, J., Lee, Y., Kim, J., Kosiorek, A.R., Choi, S., & Teh, Y.W. (2018). Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. International Conference on Machine Learning.
[3] Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., & Jitsev, J. (2022). LAION-5B: An open large-scale dataset for training next generation image-text models. ArXiv, abs/2210.08402.