ANNOUNCING DATACOMP: IN SEARCH OF THE NEXT GENERATION OF MULTIMODAL DATASETS
by: Gabriel Ilharco, 27 Apr, 2023
[ Paper ] [ Code ] [ Website ]
About a year ago, we released LAION-5B, a billion-scale open-source image-text dataset. Since then, LAION-5B has become a staple in the open-source machine learning ecosystem, powering open-source models like OpenCLIP, OpenFlamingo, and Stable Diffusion. From the beginning, we viewed LAION-5B as only the first step on this research journey and hoped that we can build the next generation of multimodal datasets both rigorously and collaboratively in the open as a research community.
Today, we are proud to introduce DataComp, a new benchmark for designing multimodal datasets. Unlike traditional benchmarks focused on modeling improvements, DataComp puts data front and center. In Datacomp, participants innovate by proposing new training sets, leaving the training code, hyper-parameters and compute fixed. As part of our competition, we are releasing CommonPool, the largest public collection of image-text pairs to date with 12.8B samples.
Along with our pool, we also release DataComp-1B, a 1.4B subset that can be used to outperform compute-matched CLIP models from OpenAI and LAION. DataComp-1B makes it possible to train a CLIP ViT-L model to better performance than a larger ViT-g model trained on LAION-2B while using 9x less training compute. Our ViT-L/14 trained on DataComp-1B obtains 79.2% zero-shot accuracy on ImageNet, substantially outperforming OpenAI's model trained with the same compute (75.5% zero-shot accuracy).
DataComp-1B is only the first dataset coming out of DataComp. We are beyond excited to continue learning about designing better datasets, and we invite you to join us on this journey!

Overview
In the past two years, we have seen multiple breakthroughs in multimodal learning. From CLIP, DALL-E and Stable Diffusion to Flamingo and GPT-4, multimodal models now show impressive generalization such as zero-shot image classification and in-context learning. Large-scale datasets have been instrumental for building these models. However, despite their importance, datasets rarely receive the same attention as model architectures or training algorithms. DataComp addresses this shortcoming in the machine learning ecosystem by introducing a benchmark where participants can rigorously explore design decisions for datasets.
Towards this goal, we present CommonPool, a large-scale dataset with 12.8B image-text pairs collected from the web—the largest dataset of its kind by a factor of 2.5x. Despite the size, our benchmark features multiple data and compute scales, and is designed to encourage participation even with a single GPU at the smallest scale.
Together with our dataset, we present simple filtering baselines that already improve upon existing methods such as the filtering used in LAION-2B. As a highlight, DataComp-1B, a 1.4B subset of our pool can be used to train a CLIP ViT-L/14 to 79.2% zero-shot accuracy on ImageNet. This model outperforms a ViT-g/14 model trained on LAION-2B by 0.7 percentage points, despite being trained with 9x less compute. It also performs substantially better than OpenAI’s ViT-L/14 model trained with the same compute budget, which gets 75.5% zero-shot accuracy on ImageNet.
We are beyond excited to continue learning about designing better datasets, and we invite you to join us in this journey!
DataComp
In DataComp, your goal is to design a dataset that produces the best possible CLIP model at a fixed compute budget. DataComp is designed with scale in mind. When participating, the first step is to choose one of the small, medium, large, or xlarge scales. Each scale comes with a corresponding pool, ranging from 12.8M samples to 12.8B samples. You can use data from that pool, or from any external data source to build your dataset depending on the competition track. After that, train your CLIP model using our public implementation of a fixed training protocol, and evaluate on our diverse suite of 38 downstream tasks.
Competition tracks: Our competition features two tracks. In the first track, CommonPool, you are only allowed to filter data from the pool we provide. On the second track, Bring Your Own Data (BYOD), you are allowed to use any data you want, as long as it doesn’t overlap with our evaluation suite.
Preprocessing and safety: We kept preprocessing of our pool to a minimum to provide a blank slate for participants. Our only initial preprocessing steps are to eliminate images that are flagged due to safety considerations or that appear in downstream evaluation datasets to avoid contamination. For the former, we take steps to eliminate illegal and explicit content and to protect the privacy of individuals, removing unsafe images and captions with automated filters and obfuscating faces in the candidate images we provide.
Multiple scales: To facilitate the study of scaling trends and accommodate participants with various levels of resources, DataComp features multiple scales of data and compute. The compute requirements vary from around 8 GPU hours at the smallest scale to over 40,000 at the largest. The pool we provide varies accordingly, from 12.8M to 12.8B samples.
Standardized training: In order to enable controlled and comparable experiments, we fix the training procedure (i.e., model architecture, optimizer, loss, hyperparameters, etc.) and compute at each scale, closely following training recipes used to train state-of-the-art CLIP models from scratch.
Evaluation: We evaluate on a diverse set of 38 downstream image classification and retrieval tasks, including distribution shifts and geographic diversity. For efficiency and simplicity, we evaluate models in a zero-shot setting, without fine-tuning on data from the downstream tasks.
Rules: We allow the use of any public data that does not overlap with our evaluation tasks. See Appendix A of our paper for more details.
What we know so far
In our paper, we present hundreds of baseline experiments with different dataset design algorithms. A key finding is that smaller, more aggressively filtered datasets can perform better than larger datasets coming from the same pool. As a highlight, we find a subset of our largest pool that performs substantially better than LAION-2B, despite being smaller (1.4B samples).
This subset, DataComp-1B, can be used to train a ViT-L/14 to 79.2% zero-shot accuracy on ImageNet, which outperforms a ViT-g/14 model trained on LAION-2B by 0.7 percentage points, despite being trained with 9x less compute. Moreover, our model performs substantially better than other ViT-L/14 models trained with the same compute budget including OpenAI's model, as seen below.
| Training data | Dataset size | # samples seen | ImageNet Acc. | Avg. performance (38 datasets) |
|---|---|---|---|---|
| OpenAI's WIT | 0.4B | 13B | 75.5 | 0.61 |
| LAION-400M | 0.4B | 13B | 73.1 | 0.58 |
| LAION-2B | 2.3B | 13B | 73.1 | 0.59 |
| LAION-2B | 2.3B | 34B | 75.2 | 0.61 |
| DataComp-1B | 1.4B | 13B | 79.2 | 0.66 |
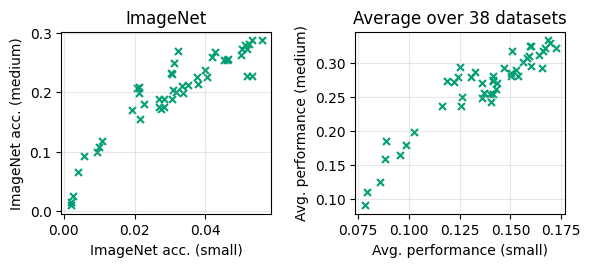
We also show that the ranking of many curation approaches is consistent across the different scales. For example, across the baselines we study, the rank correlation between ImageNet accuracy at small and large scales is 0.9. This suggests that experiments at smaller scales can provide valuable insights for larger scales, thereby accelerating investigations.
There is much more in the paper, and we think this is only the beginning. We hope you’ll join us in designing the next generation of multimodal datasets!
How do I start?
The best starting point is our github repo, which contains code for downloading our pools, training and evaluating models.
Our website www.datacomp.ai/ contains further documentation.
DataComp ICCV Workshop
In conjunction with DataComp, we are also organizing a workshop at ICCV 2023, titled Towards the Next Generation of Computer Vision Datasets. The workshop will showcase a series of DataComp submissions, along with other data-centric papers and multiple invited talks by experts in the field. Our call for papers is available at https://www.datacomp.ai/workshop.html.
Acknowledgements
We thank all of our paper authors: Samir Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt.
We also thank Amro Abbas, Jessie Chapman, Brian Cheung, Joshua Gardner, Nancy Garland, Sachin Goyal, Huy Ha, Zaid Harchaoui, Andy Jones, Adam Klivans, Daniel Levy, Ronak Mehta, Ari Morcos, Raviteja Mullapudi, Kentrell Owens, Alec Radford, Marco Tulio Ribeiro, Shiori Sagawa, Christoph Schuhmann, Matthew Wallingford, and Ross Wightman for helpful feedback at various stages of the project.
A special thanks to Stability AI and the Gauss Centre for Supercomputing e.V (compute time granted on JUWELS Booster hosted at Juelich Supercomputing Center) for providing us with compute resources to train models, without which none of this would have been possible.