LAION COCO: 600M SYNTHETIC CAPTIONS FROM LAION2B-EN
by: Christoph Schuhmann, Andreas Köpf, Richard Vencu, Theo Coombes, Romain Beaumont, 15 Sep, 2022
Author: Christoph Schuhmann, Andreas Köpf , Theo Coombes, Richard Vencu, Benjamin Trom , Romain Beaumont
We present LAION-COCO, the world’s largest dataset of 600M generated high-quality captions for publicly available web-images
Laion5B has five billion natural captions. They provide a lot of information, but could synthetic captions complement them ?
To answer this question, we use a combination of existing, publicly available models to produce high quality captions for images in the style of MS COCO.
We captioned 600M images from the english subset of Laion-5B with an ensemble of BLIP L/14 and 2 CLIP versions (L/14 and RN50x64).
With this post we release them openly today.
This will make it possible to investigate the value of generated captions to train models. We’re curious on how these synthetic captions could impact models trained on them!
Download it
The 600M samples are provided in parquet files. Columns include the original caption, the url, the top caption and a list of alternative captions with lower CLIP-similarity scores.
https://huggingface.co/datasets/laion/laion-coco
Samples

Original: LGSY 925 Sterling Silver Double Heart Rings Infinity Love Thin Rings Wedding Engagement Promise Engraved Love Rings for Women for Dainty Gift
Generated: An open ring with two hearts on it.

Original: Female Thick with Pointy Head High Heel Chelsea Ankle Boots
Generated: Red leather ankle boots with gold buckles.

Original: a group of people on horses on a beach
Generated: Several people riding horses down the beach on a cloudy day.

Original: a wall with a bunch of graffiti on it
Generated: The parking meter is near a graffiti covered building.

Original: sheeple family
Generated: A cartoon drawing of sheep watching TV with their babies.
More samples of images with their generated captions can be found here:
(no cherry picking)
http://captions.christoph-schuhmann.de/eval_laion/eval.html
Method
The method we used to generate these captions was to
- We use Blip L/14 to generate 40 captions
- Rank them using openai Clip Open AI L/14 ; selected the best 5 captions
- Rank using Open AI RN50x64 Clip model to select the best one
- Use a small, fine-tuned T0 model to roughly repair grammar and punctuation of the texts
The hyperparameters were chosen through a grid search (settings) by Andreas Köpf to best match the style ( ROUGE scores ) of MS COCO texts.
laion_idle_cap is the script that was used for this processing.
Evaluation
We evaluated these generated captions by asking human evaluators to guess whether a caption is coming from a human or an AI model. We also asked them to rate the quality on a scale from 0(bad) to 5 (good).
In a first round we presented the evaluators each 200 samples, that contained 100 AI generated and 100 human written MS COCO captions.
Observations
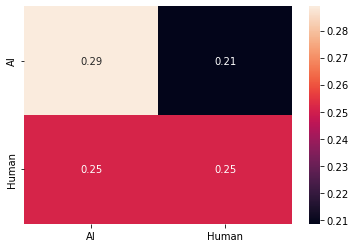
GT: Y-Axis
Annotation: X-Axis
Mean rating & standard deviation of samples, that were written by a human:
Mean: 3.98
Stdev: 0.99
Mean rating & standard deviation of samples, that were written by an AI
Mean: 3.89
Stdev: 1.12
Mean rating & standard deviation of samples, where the annotator believed they were written by a human:
Mean: 4.44
Stdev: 0.61
Mean rating & standard deviation of samples, where the annotator believed they were generated by an AI
Mean: 3.50
Stdev: 1.15
Interpretation
It is very interesting that the mean scores of the samples generated by humans and generated by the model are very similar. We also notice that the standard deviation of the generated captions is a little bit higher.
We hypothesize that most in most cases the quality of the generated captions is perceived as as good as the quality of the human written captions.
But sometimes the captioning model obviously fails and the quality of the results is pretty low because the model doesn't relevant understand concepts about what is going on in the picture, because it's knowledge is not grounded in a sufficiently sophisticated world model.
Failure cases

“Two people posing for the camera in their wedding attire, one with an umbrella over his head and another with long red hair.”

“An older man having a heart attack, with his hand on the chest.”
When we remove all samples from the evaluations that have ratings of either 0 or 1, we Observe that the mean ratings and standard deviations move closer together.
Scores without ratings of 0 and 1
Mean rating & standard deviation of samples, that were written by a human:
Mean: 4.07
Stdev: 0.81
Mean rating & standard deviation of samples, that were written by an AI
Mean: 4.02
Stdev: 0.94
The mean ratings of the generated captions are still a little bit lower and the standard deviation is still a little bit higher, but the trend is pretty clear. By removing samples with rating 2, the gap between the qualities would probably decrease even further.
Presentation only generated captions:
In a next step, we presented the human evaluators 400 captions that were only generated by the model (no human written captions in between):
Mean rating of all samples
3.81
Standard deviation of all samples
0.94
% rated as human
47.5
% rated as AI
52.5
We observe that the human evaluators thought in 47.5% of all cases, that the captions were written by a human. This makes us confident that our captains are on average pretty good. When we told the evaluators later that all captions were generated by the model they told us that it was very hard for them to judge whether a caption was written by a model or a human, and that it only was easy for them in obvious failure cases.
Conclusions
We conclude that Our ensemble of BLIP and CLIP is already pretty good and capable of generating captions with a quality that is on average pretty close to the human written captions of MS Coco.
It would be very interesting for future work to let people rate our generated captions at larger scale and then filter out the samples with low rating values. These results could be used to train models to rate the quality of captions and to predict whether a caption looks like a generated or a human written caption.
And even without further automated filtering, an ensemble of our captions and human evaluators would be a pretty good workflow to curate high quality captions at much lower costs than if we would ask humans to write them from scratch.
Credit assignments
- Christoph Schuhmann lead the project, implemented a first version of the code, ran most of the generations & conducted the human evaluations
- Andreas Köpf conducted the hyperparameter search & wrote the code to execute BLIP + CLIP filtering at scale
- Theo Coombes managed the server that coordinated which GPU worker got which part of LAION to work on
- Romain Beaumont packaged the .json into parquet files, sent to HF and wrote the first draft of this post
- Richard Vencu provided the infra structure to use the idle compute for this project
- Benjamin Trom wrote code that help us to convert the .json files to parquet
We thank stability.ai for providing the compute used to generate the captions in the dataset.