OPENFLAMINGO V2: NEW MODELS AND ENHANCED TRAINING SETUP
by: Anas Awadalla* and Irena Gao*, 28 Jun, 2023
About three months ago, we announced OpenFlamingo, an open-source effort to replicate DeepMind's Flamingo models.
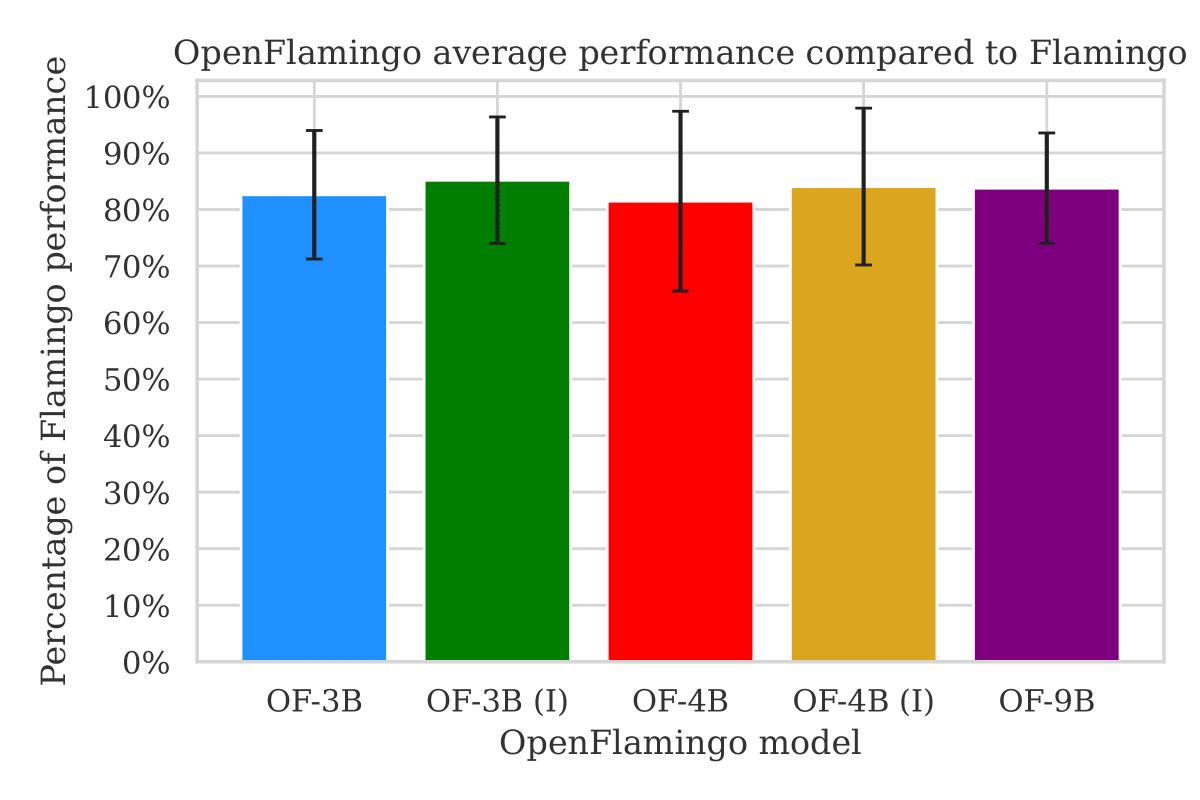
Today, we are excited to release five trained OpenFlamingo models across the 3B, 4B, and 9B scales. These models are based on Mosaic’s MPT-1B and 7B and Together.xyz’s RedPajama-3B, meaning they are built on open-source models with less restrictive licenses than LLaMA. When averaging performance across 7 evaluation datasets, OpenFlamingo models attain more than 80% of the performance of their corresponding Flamingo model. OpenFlamingo-3B and OpenFlamingo-9B also attain more than 60% of fine-tuned SOTA performance using just 32 in-context examples.
We’ve also improved our open-source training and evaluation code, adding support for Fully Sharded Data Parallel (FSDP) and new datasets (TextVQA, VizWiz, HatefulMemes, and Flickr30k) to the evaluation suite.
Technical overview
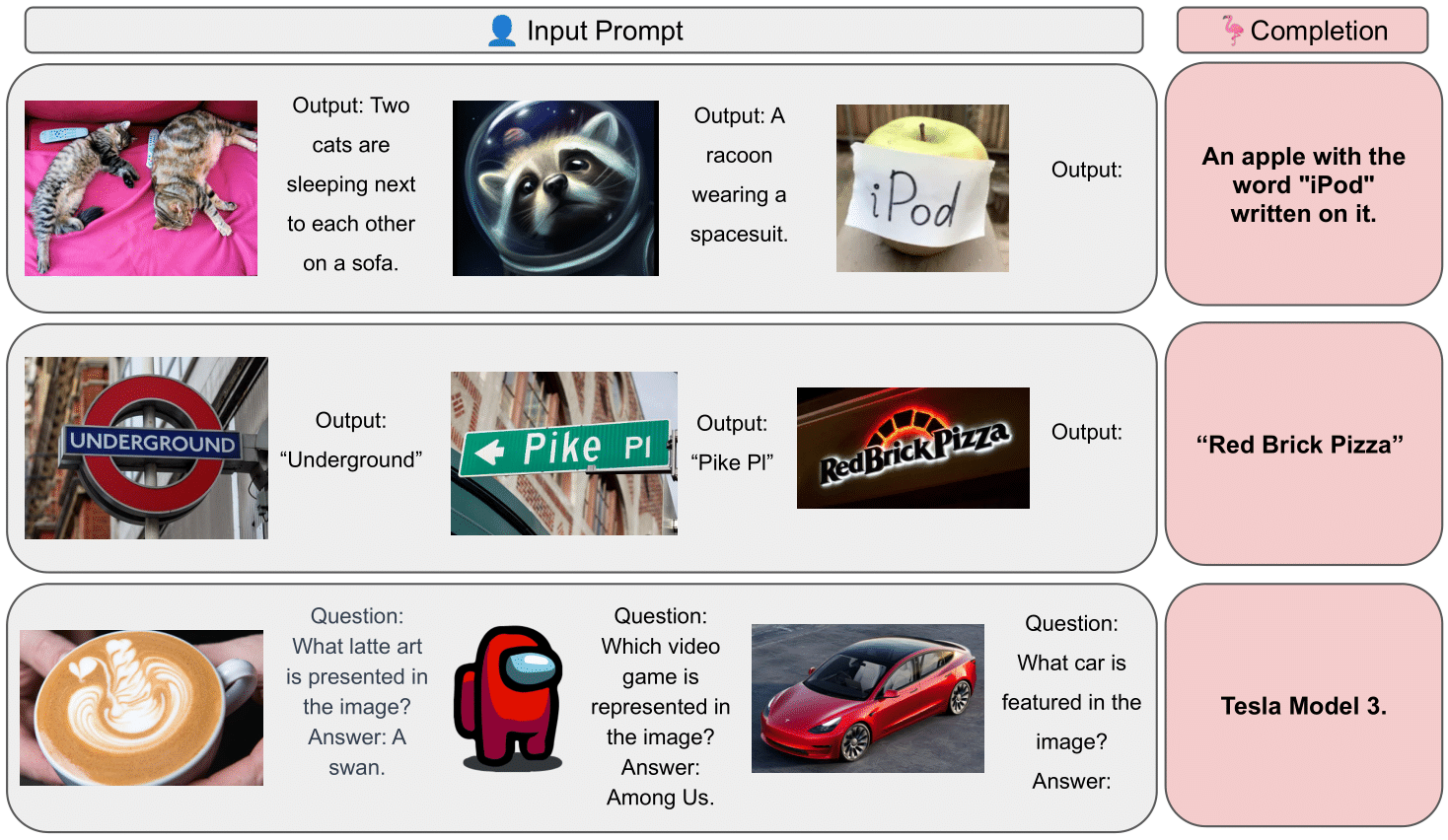
OpenFlamingo models process arbitrarily interleaved sequences of images and text to output text. This allows the models to accept in-context examples and solve tasks like captioning, visual question answering, and image classification.
We follow the Flamingo modeling paradigm, augmenting the layers of a pretrained, frozen language model such that they cross-attend to visual features when decoding. Following Flamingo, we freeze the vision encoder and language model but train the connecting modules on web-scraped image-text sequences. Specifically, we use a mixture of LAION-2B and Multimodal C4. **
** The 4B-scale models were also trained on experimental ChatGPT-generated (image, text) sequences, where images were pulled from LAION. We are working to release these sequences soon.
Model release
We have trained five OpenFlamingo models across the 3B, 4B, and 9B parameter scales. These models build off of OpenAI’s CLIP ViT-L/14 as a vision encoder and open-source language models from MosaicML and Together.xyz. At the 3B and 4B scales, we have trained models both with standard and instruction-tuned language model backbones.
| # params | Language model | (Language) instruction tuned? |
|---|---|---|
| 3B | mosaicml/mpt-1b-redpajama-200b | No |
| 3B | mosaicml/mpt-1b-redpajama-200b-dolly | Yes |
| 4B | togethercomputer/RedPajama-INCITE-Base-3B-v1 | No |
| 4B | togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | Yes |
| 9B | mosaicml/mpt-7b | No |
Note that as part of the move to v2, we are deprecating our previous LLaMA-based checkpoint. However, you can continue to use our older checkpoint using the new codebase.
Evaluation
We evaluated our models on vision-language datasets across captioning, VQA, and classification tasks. As shown below, the OpenFlamingo-9B v2 model shows considerable improvement over our v1 release.
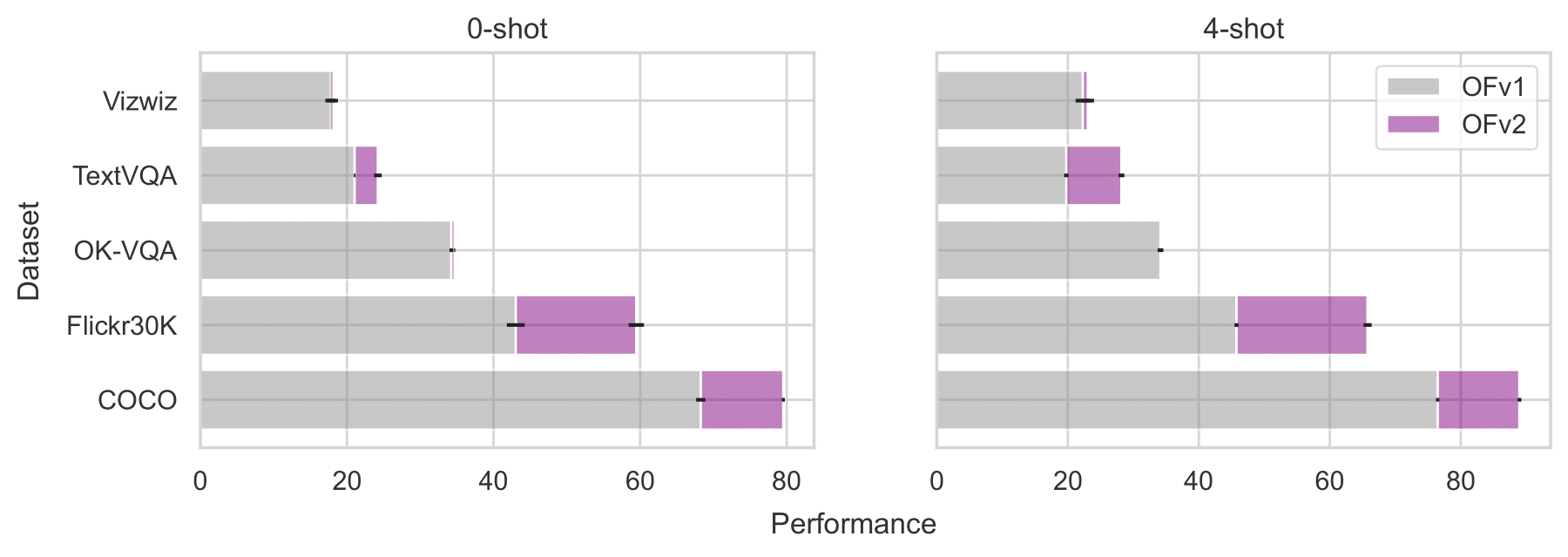
Below, we aggregate model performances across 7 evaluation datasets and 5 in-context evaluation settings (0-shot, 4-shot, 8-shot, 16-shot, and 32-shot). Averaged across these settings, OpenFlamingo (OF) models attain more than 80% of corresponding Flamingo performance, where we compare OF-3B and OF-4B with Flamingo-3B, and OF-9B with Flamingo-9B. Error bars are standard deviations over datasets and evaluation settings.
Next, we report performance relative to fine-tuned SoTAs listed on PapersWithCode*. With 32 in-context examples, OpenFlamingo-3B and OpenFlamingo-9B models attain more than 55% of fine-tuned performance, despite only being pre-trained on web data. On average, OpenFlamingo models trail their DeepMind counterparts by around 10% 0-shot and 15% 32-shot.
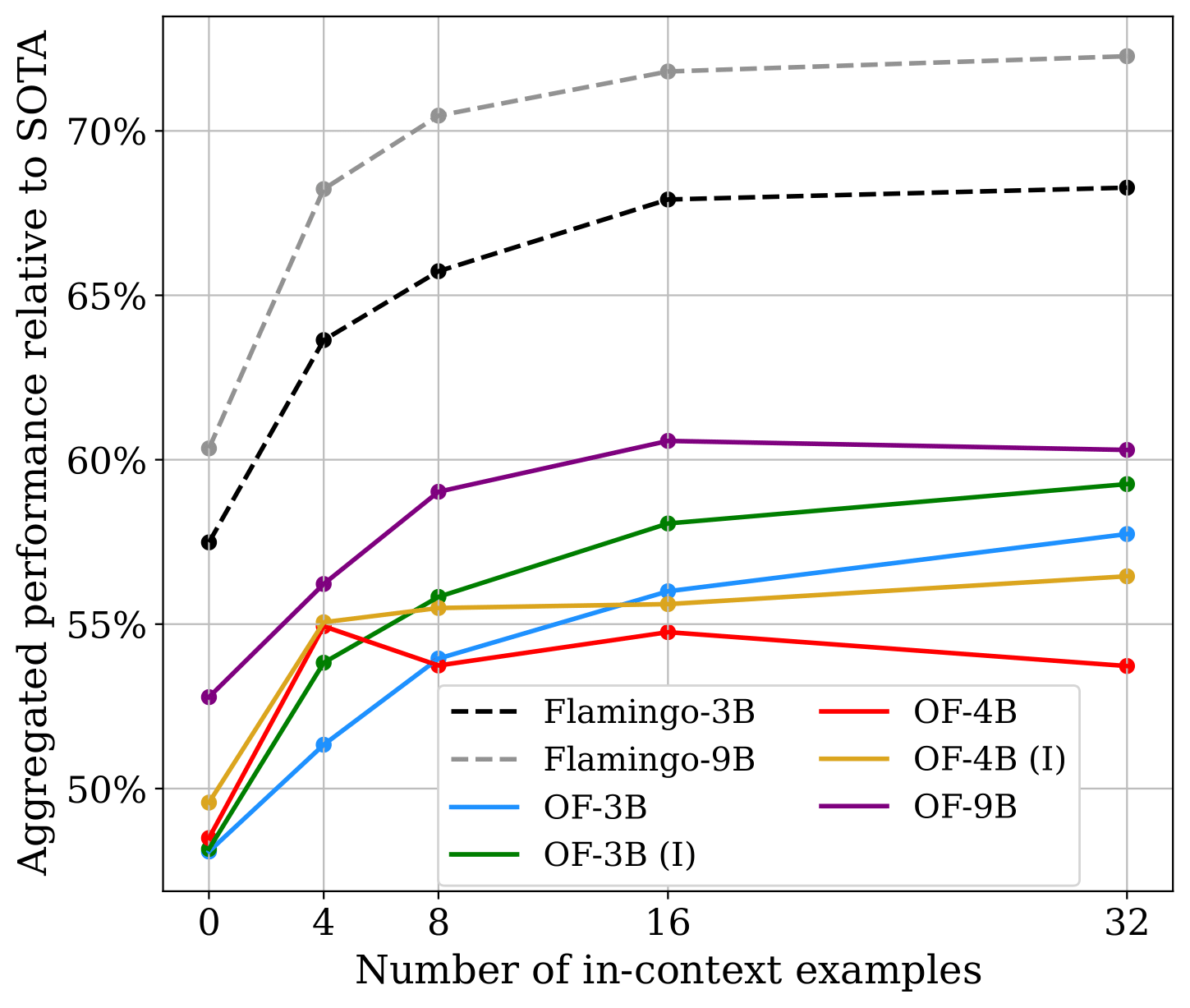
Below, we present per-dataset results. We observe that on some datasets, OpenFlamingo models (especially the 4B ones) generalize poorly across the number of in-context examples. We hypothesize that this behavior stems from the quality of our pre-training data.
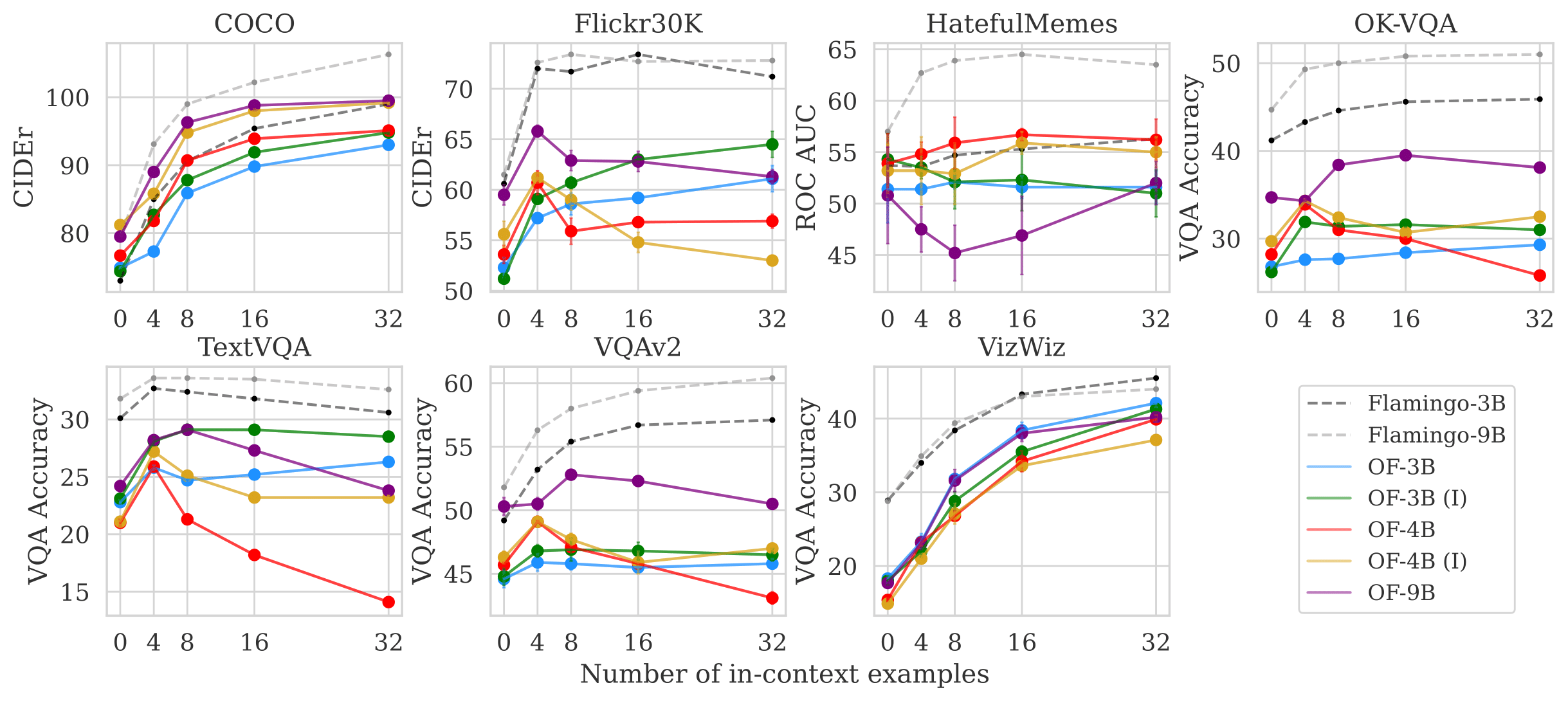
* numbers pulled on Monday, June 19
Next steps and codebase updates
OpenFlamingo remains an active research project, and we continue to work on training and releasing high-quality multimodal models. As next steps, we’re particularly interested in improving the quality of our pre-training data.
We were thrilled by the many cool projects building off of our first release such as Otter and Multimodal-GPT. We encourage the community to continue using OpenFlamingo. To make training OpenFlamingo models more accessible, we have added support for Fully Sharded Data Parallel (FSDP) and gradient checkpointing. For context, in experiments, we were able to fit a 9B scale OpenFlamingo model on 8 A100 40GB gpus using FSDP and gradient checkpointing. We’ve also added scripts for packaging our training data into the expected Webdataset form.
If you’re interested in contributing to our codebase, including our evaluation suite, please join us at the OpenFlamingo github repository.
Safety and ethical considerations
OpenFlamingo models inherit the risks of their parent models, especially the language model. As an open-source research effort, we highly value open, accessible, reproducible multimodal model research; however, it is crucial to be aware that these models are trained on web data and have not been finetuned for safety, and thus may produce unintended, inappropriate, unreliable, and/or inaccurate outputs. Please use caution before deploying OpenFlamingo models in real applications. We also hope that OpenFlamingo enables further safety and reliability research to address these issues.
Contributors
Thanks to: Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt
Acknowledgements
We would like to thank Jean-Baptiste Alayrac and Antoine Miech for their advice and Stability AI for providing us with compute resources to train these models.