INTRODUCING OPENLM
by: OpenLM team, 26 Sep, 2023

Introduction
We release OpenLM a simple and minimalist PyTorch codebase for training medium-sized language models. OpenLM is designed to maximize GPU utilization and training speed, and is easy to modify for new language model research and applications.
We validate OpenLM by training two language models, OpenLM-1B and OpenLM-7B, on 1.6T and 1.25T tokens of text, respectively. We evaluate these models on standard zero-shot text classification and multiple choice tasks and find that OpenLM-1B outperforms many popular, similarly sized models such as OPT-1.3B and Pythia-1B. OpenLM-7B achieves similar performance to LLAMA-7B and MPT-7B.
In this blogpost, we briefly describe the training data, model, evaluation setup, and overall results. We also describe exciting future work we plan to pursue with these models and our OpenLM framework.
Model and Data Release
All models and training data (tokenized and shuffled) are available on Huggingface at the following links:
We are working on releasing intermediate checkpoints.
Data
We train our models on a collection of text totaling 1.6T tokens. The training data comes from the following sources:
| Dataset | Tokens | Percentage |
|---|---|---|
| RedPajama | 1157.3B | 72.6% |
| Pile | 336.2B | 21.1% |
| S2ORC | 48.9B | 3.1% |
| Pile of Law | 27.1B | 1.7% |
| RealNews | 25.0B | 1.6% |
| Total | 1594.5B | 100% |
We do not perform additional preprocessing on the text, and take the data as is from the original sources. To train our model on these data sources, we simply use the following data mix: 72.6% on RedPajama, 27.4% everything else. This follows the given distribution of data in the table above.
Models
The models we train follow the basic architecture proposed by LLaMA. The two differences are that we use the GPT-NeoX tokenizer, which we found to be effective in early experiments, and we use LayerNorm instead of RMSNorm, because we haven’t yet added a fused RMSNorm operation.
The 1B model is trained with AdamW (LR 1e-3, weight decay 0.1) on 128 A100 40GB GPUs, with a global batch size of 2M tokens.
The 7B model is trained with AdamW (LR 3e-4, weight decay 0.1) on 256 A100 40GB GPUs, with a global batch size of 4M tokens.
The training speed for the 7B model is 2300 tokens/s/GPU. For model parallelism we use PyTorch FSDP.
Aside from the model, the codebase closely follows OpenCLIP which has been tested on around 1,000 GPUs.
Evaluation Setup
During training, we track validation loss using a held out subset of recent papers from the authors of the OpenLM library, breaking news at the time of development, and the OpenLM codebase.
After training, we use the LLM-foundry to evaluate model performance on the 13 zero-shot tasks used to evaluate MPT-7B and LLaMA 7B in the MPT-7B release. We additionally evaluate 5-shot MMLU performance.
Results
Validation Loss
Here, we display the validation loss for up to 1T tokens of training for both the OpenLM-1B and 7B models:
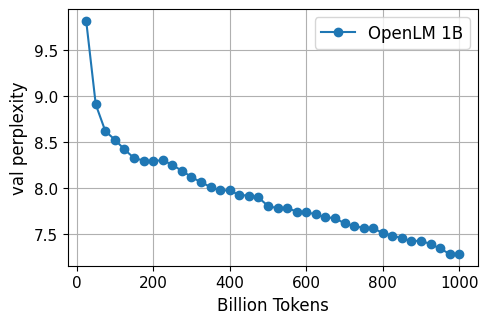
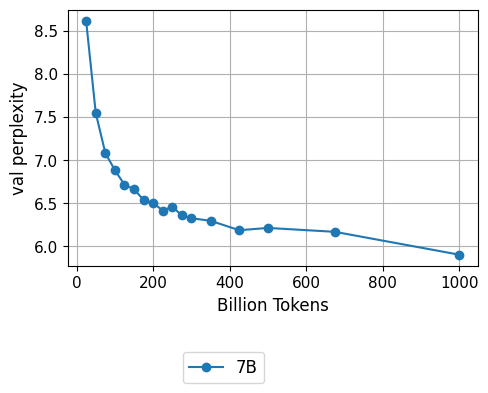
Downstream Evaluations
Here, we display the zero-shot evaluation results of OpenLM-1B throughout training:
| OpenLM-1B | 250B tokens | 500B tokens | 750B tokens | 1T tokens | 1.25T tokens | 1.5T tokens | 1.6T tokens |
|---|---|---|---|---|---|---|---|
| Training progress | 16% complete | 31% complete | 47% complete | 63% complete | 78% complete | 94% complete | 100% complete |
| arc_challenge | 0.27 | 0.28 | 0.29 | 0.28 | 0.29 | 0.31 | 0.31 |
| arc_easy | 0.49 | 0.50 | 0.51 | 0.53 | 0.54 | 0.56 | 0.56 |
| boolq | 0.60 | 0.61 | 0.62 | 0.62 | 0.65 | 0.64 | 0.65 |
| copa | 0.71 | 0.70 | 0.70 | 0.78 | 0.71 | 0.73 | 0.70 |
| hellaswag | 0.50 | 0.54 | 0.54 | 0.57 | 0.59 | 0.61 | 0.61 |
| lambada_openai | 0.56 | 0.57 | 0.61 | 0.61 | 0.65 | 0.65 | 0.66 |
| piqa | 0.70 | 0.70 | 0.71 | 0.72 | 0.73 | 0.74 | 0.74 |
| winogrande | 0.55 | 0.57 | 0.58 | 0.59 | 0.61 | 0.60 | 0.60 |
| MMLU | 0.24 | 0.24 | 0.24 | 0.23 | 0.26 | 0.24 | 0.25 |
| Jeopardy | 0.01 | 0.02 | 0.01 | 0.01 | 0.04 | 0.09 | 0.10 |
| Winograd | 0.75 | 0.77 | 0.77 | 0.79 | 0.81 | 0.80 | 0.79 |
| Average | 0.49 | 0.50 | 0.51 | 0.52 | 0.53 | 0.54 | 0.54 |
As a comparison, here are the zero-shot results of similarly sized baselines. Our model achieves similar performance to OPT-IML-1.3B, an instruction-tuned model.
| 1B Baselines | OPT-1.3B | Pythia-1B | Neox-1.3B | OPT-IML-1.3B | OpenLM-1B |
|---|---|---|---|---|---|
| arc_challenge | 0.27 | 0.26 | 0.26 | 0.30 | 0.31 |
| arc_easy | 0.49 | 0.51 | 0.47 | 0.58 | 0.56 |
| boolq | 0.58 | 0.61 | 0.62 | 0.72 | 0.65 |
| copa | 0.75 | 0.68 | 0.72 | 0.73 | 0.70 |
| hellaswag | 0.54 | 0.49 | 0.48 | 0.54 | 0.61 |
| lambada_openai | 0.59 | 0.58 | 0.57 | 0.57 | 0.66 |
| piqa | 0.72 | 0.70 | 0.72 | 0.73 | 0.74 |
| winogrande | 0.59 | 0.53 | 0.55 | 0.59 | 0.60 |
| MMLU | 0.25 | 0.26 | 0.26 | 0.30 | 0.25 |
| Jeopardy | 0.01 | 0.00 | 0.00 | 0.12 | 0.10 |
| Winograd | 0.74 | 0.71 | 0.75 | 0.73 | 0.79 |
| Average | 0.50 | 0.48 | 0.49 | 0.54 | 0.54 |
Next, we display the zero-shot evaluation results of OpenLM-7B throughout training:
| OpenLM-7B | 275B tokens | 500B tokens | 675B tokens | 775B tokens | 1T tokens | 1.25T tokens |
|---|---|---|---|---|---|---|
| Training progress | 17% complete | 31% complete | 42% complete | 48% complete | 63% complete | 78% complete |
| arc_challenge | 0.35 | 0.35 | 0.36 | 0.37 | 0.39 | 0.39 |
| arc_easy | 0.60 | 0.61 | 0.62 | 0.62 | 0.63 | 0.66 |
| boolq | 0.67 | 0.66 | 0.69 | 0.69 | 0.70 | 0.70 |
| copa | 0.75 | 0.79 | 0.75 | 0.80 | 0.80 | 0.78 |
| hellaswag | 0.64 | 0.67 | 0.68 | 0.68 | 0.69 | 0.70 |
| lambada_openai | 0.67 | 0.68 | 0.69 | 0.70 | 0.70 | 0.70 |
| piqa | 0.75 | 0.76 | 0.76 | 0.76 | 0.77 | 0.77 |
| winogrande | 0.62 | 0.65 | 0.65 | 0.65 | 0.67 | 0.67 |
| MMLU-0 shot | 0.25 | 0.25 | 0.27 | 0.27 | 0.28 | 0.30 |
| Jeopardy | 0.15 | 0.18 | 0.23 | 0.22 | 0.16 | 0.21 |
| Winograd | 0.82 | 0.81 | 0.84 | 0.84 | 0.85 | 0.86 |
| Average | 0.57 | 0.58 | 0.60 | 0.60 | 0.60 | 0.61 |
| Task | OpenLM-7B | LLAMA-7B | MPT-7B |
|---|---|---|---|
| arc_challenge | 0.39 | 0.41 | 0.39 |
| arc_easy | 0.66 | 0.65 | 0.67 |
| boolq | 0.70 | 0.77 | 0.75 |
| copa | 0.78 | 0.78 | 0.81 |
| hellaswag | 0.70 | 0.75 | 0.76 |
| lambada_openai | 0.70 | 0.74 | 0.70 |
| piqa | 0.77 | 0.79 | 0.80 |
| winogrande | 0.67 | 0.68 | 0.68 |
| MMLU-0 shot | 0.30 | 0.30 | 0.30 |
| Jeopardy | 0.21 | 0.33 | 0.31 |
| Winograd | 0.86 | 0.81 | 0.88 |
| Average | 0.61 | 0.64 | 0.64 |
| MMLU-5 shot | 0.34 | 0.34 |
Consistent with the validation loss, our models continue to improve in zero-shot performance even late in training. At 1.25T tokens, OpenLM-7B matches or outperforms LLaMA-7B or MPT-7B on 7 out of 11 tasks.
Future Work
OpenLM has already enabled new language modeling research, for example in the development of low-risk language models trained on permissively licensed text. We plan to use OpenLM to support a variety of new research directions, including multimodal models, mixture of experts, and dataset composition. We also plan to scale up OpenLM so it supports training larger models.
Team and acknowledgements
The OpenLM team currently consists of: Suchin Gururangan*, Mitchell Wortsman*, Samir Yitzhak Gadre, Achal Dave, Maciej Kilian, Weijia Shi, Jean Mercat, Georgios Smyrnis, Gabriel Ilharco, Matt Jordan, Reinhard Heckel, Alex Dimakis, Ali Farhadi, Vaishaal Shankar, Ludwig Schmidt.
Code is based heavily on open-clip developed by a team including Ross Wightman, Romain Beaumont, Cade Gordon, Mehdi Cherti, Jenia Jitsev, and open-flamingo, developed by a team including Anas Awadalla and Irena Gao. Additional inspiration is from lit-llama.
We thank Stability AI for providing the compute for this project, the RedPajama team for their dataset, Sarah Pratt for logo design, IFML, and Toyota Research Institute. We also thank the following people for helpful advice and feedback throughout the project: Jonathan Frankle, Daniel King, Luca Soldaini.