OPEN-SCI-REF 0.01: OPEN BASELINES FOR LANGUAGE MODEL AND DATASET COMPARISON
by: Marianna Nezhurina, Joerg Franke, David Salinas, Jenia Jitsev; open-sci collective, openEuroLLM team, LAION, 18 Aug, 2025
We introduce and release open-sci-ref 0.01 - a research dense transformer model family with all the intermediate checkpoints trained on 8 different well established reference datasets on various model (0.13B - 0.4B - 1.3B - 1.7B) and token (50B, 300B, 1T) scales to serve as baselines for comparison and for studies on training dynamics. Our release includes all intermediate model weights, logs and training workflow code to enable easy learning procedure comparison on available reference scales and datasets and to support future research.
Models and intermediate checkpoints: HugginFace open-sci-ref-0.01 collection
Usage infos and release overview: open-sci-ref-0.01 release repository (continuously updated)
ArXiv paper
Introduction and motivation
Foundation models - models that show transfer across various conditions and tasks after generic pre-training on large volumes of diverse data, exhibiting scaling laws for predictable stronger transfer with increasing pre-training scales - are at the core of modern machine learning, holding promise for solving fundamental problems of generalization and efficient learning. To make guided progress in researching foundation models and datasets necessary for their creation, it is necessary to perform fully controllable and reproducible comparison of various learning procedures. Ideally, such a comparison should allow to identify learning procedures that produce stronger generalization than others, identify components of the procedure that lead to stronger generalization, while being reproducible for any other third party to validate the findings.
This release makes a step towards establishing grounds for performing such comparisons. We provide a set of training runs and resulting base language models to serve as reference baselines that can be used for comparing any other training and check its sanity and quality relative to the established baselines across various important open reference datasets. For the first step, we chose standard dense transformers similar to the previous works like Pythia (Pythia repo), DCLM (DCLM repo), OLMo (OLMo repo), PolyPythias (PolyPythias repo) that use fully open, reproducible training pipelines and also provide intermediate checkpoints for studying training dynamics. It is closely related to recent DataDecide (DataDecide repo) work that goes up to 1B model scale and 100B tokens scales, while with our release we provide baseline reference for larger 1.3B and 1.7B scales on larger 1T tokens scales, including recent NemoTron-CC HQ as strong reference dataset and variants with 4k, 8k and 16k context length used during pre-training. We show how reference training performed on various scales can be used for open dataset comparison, confirming NemoTron-CC HQ (which is a mix of real and synthetic data) as consistently the best pre-training dataset, followed by DCLM-baseline and FineWeb-Edu. We show how comparison to reference baselines across scales can be used to test claims about model or dataset quality, e.g. pointing to pitfalls in multilingual training and datasets. We release all the trained models, intermediate checkpoints and logs to facilitate further studies. We also provide necessary sanity checks and baselines for building and studying strong base models in cooperation with OpenEuroLLM.
Experimental procedure
Details on datasets, tokenization, training
We consider 8 datasets: 7 reference datasets C4, Pile, SlimPajama, FineWeb-Edu-1.4T (v1.0.0), DCLM-baseline, Nemotron-CC-HQ, HPLT-2.0 (english subset), and CommonCorpus as baseline for a multilingual raw data pool. We tokenize datasets using GPT-NeoX-20B tokenizer, resulting in vocabular size of 50304. For all datasets, we train reference dense transformer models with 130M, 400M, 1.3B and 1.7B parameters with Megatron-LM. Following other strong reference models like Llama, Qwen, DCLM and DeepSeek, we employ qk-norm in the model architecture for more stable training and constant learning rate with linear cooldown schedule (also known as WSD or trapezoid schedule), which allows easier continued training and is also better suitable for measurements necessary for scaling law derivation across different token budgets (see eg Porian et al, NeurIPS 2025). We evaluate every intermediate checkpoint with zero-shot and few-shot benchmarks, namely Copa, Openbookqa, Lambada_openai, Winogrande on 0-shot setting, MMLU in 5-shot and Commonsense-qa, Piqa, Arc-challenge, Arc-easy, Hellaswag, Boolq with 10-shot, resulting in 11 evals in total.
Model architecture
We follow a custom design starting from Llama architecture. Different from standard Llama, we employ biases in all linear layers (QKV projections, attention and FFN), as experiments on 50BT scale have shown that removing biases results in performance deterioration, and also use qk-norm for training stabilization. We use SwiGLU and tied embedding weights for all models. See Tab.1 for the model configs for various scales.
| Params (B) (Non-Emb + Emb) |
Layers | Hidden | Heads | FFN Hidd |
Mem | FLOPS (6N) |
|---|---|---|---|---|---|---|
| 0.1 + 0.03 = 0.13 | 22 | 512 | 8 | 2256 | 0.89GB | 7.8 × 108 |
| 0.35 + 0.05 = 0.40 | 22 | 1024 | 16 | 3840 | 2.88GB | 2.4 × 109 |
| 1.21 + 0.10 = 1.31 | 24 | 2048 | 32 | 5440 | 7.544GB | 7.9 × 109 |
| 1.61 + 0.10 = 1.71 | 24 | 2048 | 32 | 8192 | 9.884GB | 1.0 × 1010 |
Table 1: Open-sci-ref model architecture and scales. Tied embedding weights are used for all configs.
Hyperparameter tuning
We perform hyperparameter tuning measuring test loss on C4 and FineWeb-Edu, selecting hyperparameters that result in lowest test loss on the datasets using 50B training runs with 1.3B model scale. We first experimented with standard cosine learning rate schedule, tuning hyperparams to match the HuggingFace reference models trained for 350B on C4 and FineWeb-Edu.
| Tokens | Global bs (tokens) |
iters | lr | warmup |
|---|---|---|---|---|
| 50B | 2.65M | 18839 | 3 × 10-3 | 6000 |
| 50B | 4.03M | 12406 | 6 × 10-3 | 1000 |
| 300B | 2.09M | 143052 | 3 × 10-3 | 5000 |
Table 2: Hyperparameters for cosine learning rate schedule.
After achieving the match and thus checking the training procedure sanity, we switched to constant learning + cooldown (WSD) schedule and tuned hyperparameters until we matched or outperformed results obtained with cosine learning rate schedule on both 50B and 300B token budgets for 1.3B model scale, which is still small enough for the tuning experiments to be affordable. The tuned WSD schedule training procedure was then used for all follow up experiments and all model scales (0.13B, 0.4B, 1.3B, 1.7B). Tuned procedure uses weight decay of 0.05, global batch size of 4M tokens, cooldown of 20% of total training duration. Warmup and learning rate depend on the chosen total token budget. For larger token budgets > 300B, a large warmup of 25000 iterations turned out to give performance gains. See Tab. 3 for the overview of tuned configurations with WSD lr schedule which we use in all follow up experiments.
| Tokens | Global bs (tokens) |
iters | learning rate |
warmup | cooldown (20%) |
|---|---|---|---|---|---|
| 50B | 2.65M | 18839 | 2 × 10-3 | 6000 | 3767 |
| 50B | 4.12M | 11921 | 4 × 10-3 | 1000 | 2384 |
| 300B | 2.09M | 143052 | 1 × 10-3 | 5000 | 28610 |
| 300B | 4.12M | 72661 | 4 × 10-3 | 25000 | 14532 |
| 1T | 4.12M | 242204 | 4 × 10-3 | 25000 | 48440 |
Table 3: Hyperparameters for WSD learning rate schedule.
Sanity check by comparing to existing open references
To make sure the training procedure we use for creating reference baseline models is good enough, we perform comparison to already established reference baselines on open datasets C4 and FineWeb-Edu, making use of open HuggingFace (HF) models with 1.7B scale, trained on 350B tokens (termed HF-ref). We evaluate both HF-ref and open-sci-ref on a broad set of standardized benchmarks (see Tab. 4). As we see that the scores for open-sci-ref matches or outperforms HF-ref (despite HF-ref having slight advantage of 50B more tokens), we can consider the training procedure to be well established and tuned for a given 1.7B model scale, which allows us to proceed with further experiments on other scales after ensuring basic training sanity. This highlights the importance of well established, open reference baselines for performing research.
| Model | Dataset | Tokens | Params (B) |
Compute (FLOPS) |
Avg | arc-c [10] |
arc-e [10] |
hellaswag [10] |
mmlu [5] |
copa [0] |
lambada [0] |
wino [0] |
open bookqa[0] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HF-ref-1.7B | C4 | 350B | 1.7 | 3.57 × 1021 | 0.506 | 0.32 | 0.66 | 0.64 | 0.25 | 0.74 | 0.56 | 0.58 | 0.30 |
| open-sci-ref-1.7B | C4 | 300B | 1.7 | 3.06 × 1021 | 0.548 | 0.34 | 0.67 | 0.68 | 0.26 | 0.81 | 0.59 | 0.63 | 0.40 |
| HF-ref-1.7B | FineWeb-Edu | 350B | 1.7 | 3.57 × 1021 | 0.541 | 0.46 | 0.77 | 0.62 | 0.25 | 0.78 | 0.50 | 0.58 | 0.37 |
| open-sci-ref-1.7B | FineWeb-Edu | 300B | 1.7 | 3.06 × 1021 | 0.549 | 0.44 | 0.75 | 0.63 | 0.26 | 0.76 | 0.52 | 0.61 | 0.42 |
Table 4: Comparing HuggingFace (HF) and open-sci-ref reference baselines on C4 and FineWeb-Edu-1.4T using standardized evals. [n] provides few shot numbers. Open-sci-ref (300B tokens) matches or outperforms the results of HF (350B tokens) reference baseline (despite slight advantage of having 50B tokens more for HF baseline), confirming the sanity of the training procedure using the same open reference datasets and same eval procedure.
Results: dataset comparison and reference baselines on various scales
We compare in Fig. 1 the average performance (across all 11 evals) when training our reference models on different datasets using 300B tokens scale. It can be seen clearly that current state-of-the-art datasets such as Nemotron-cc-hq and DCLM provide better performance, with gaps becoming much stronger pronounced for larger model scales, while still being significant for smaller model scales, with dataset ranking of top performing datasets remaining stable across model scales. CommonCorpus as a baseline for a multilingual raw data pool performs expectedly worse than other reference datasets that were filtered with focus on english and are composed as datasets ready for model training. This highlights an important difference between raw data pools that cannot claim training dataset status and require additional effort of identifying and executing proper filtering, and training datasets where creators already spent effort to identify and execute filtering procedure to make dataset already suitable for training. The visible increase in performance marked by stronger upwards slope starting at 240B tokens (60B before training's end) is due to WSD schedule cooldown period kicking in at this time (20% of full 300B token budget), cooling learning rate down to 0.
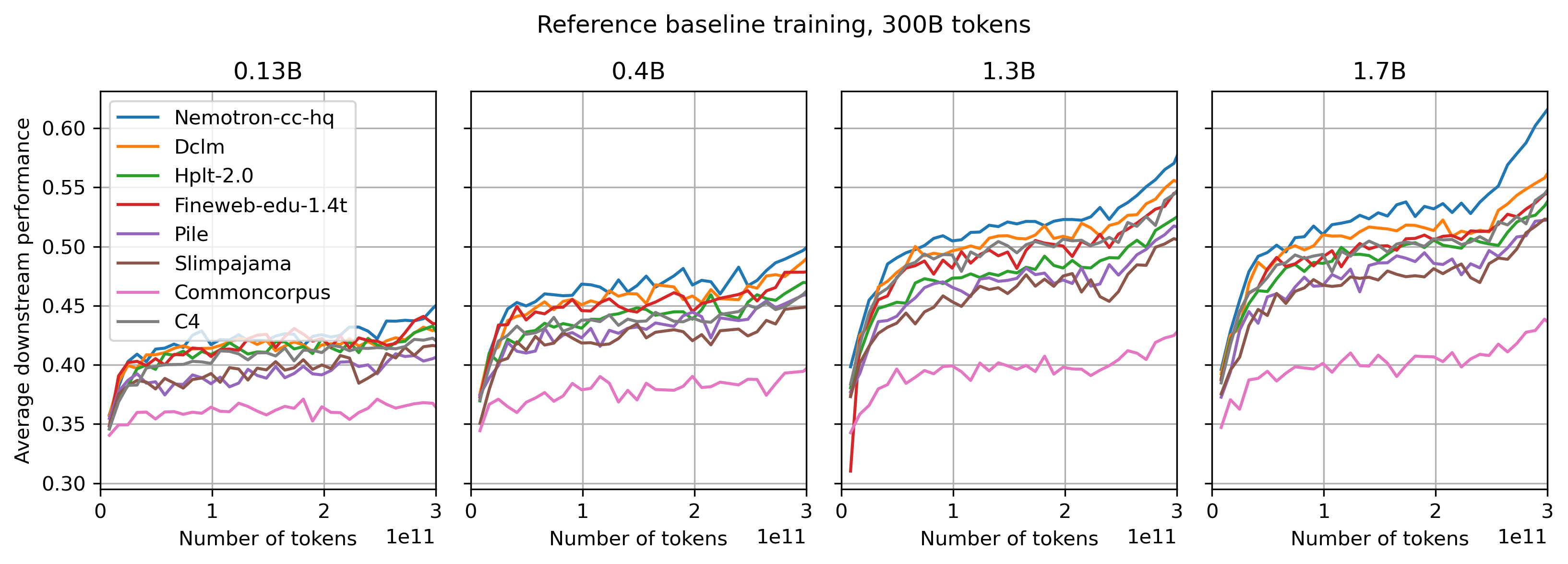
Figure 1: Comparing average performance across 11 evaluation benchmarks (Copa[0], Openbookqa[0], Lambada[0], Winogrande[0], MMLU[5] Commonsense-qa[10], Piqa[10], Arc-challenge[10], Arc-easy[10], Hellaswag[10], Boolq[10], [n] standing for few-shot number) for 8 different datasets trained using 300B tokens on different model scales. Dataset ranking is visible and consistent across model scales, with differences becoming more pronounced at larger model scales.
Fig. 2 shows dataset comparison on each of the evaluations for the 1.7B model trained on 300B tokens of each corresponding reference dataset. We see pronounced differences between datasets on some of the evals, with consistent dataset ranking. On MMLU, dataset comparison is hard due to lack of the signal for the all datasets but Nemotron-CC-HQ. Nemotron-CC-HQ contains a large portion of synthetically generated data that consists of instruction-like samples with various re-phrasing. Training on such data also boosts ability to deal with multiple choice question (MCQ) format like used in MMLU, which makes the score goes strongly up, while other datasets lead to performance close to random guessing (0.25). This highlights necessity to choose evals that are able to provide enough continuous signal without sudden jumps, especially when evaluating models in early stage of learning and at smaller scales, where capabilities are still underdeveloped. Again, strong performance jump close to the end of the training, starting 60B tokens before finishing, is due to cooldown that drops learning rate down to zero.
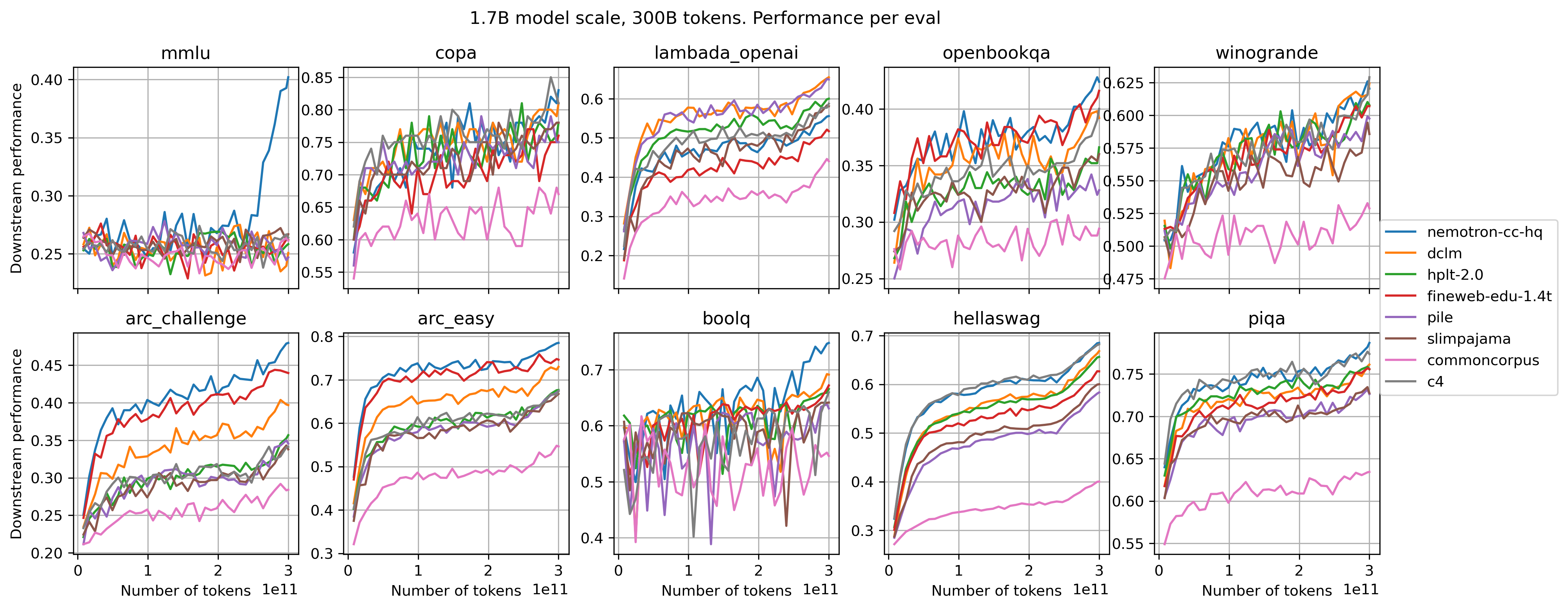
Figure 2: Comparing performance of 1.7B model trained on reference datasets for 300B tokens. Comparison shown on 10 different evals. While some evals give clear dataset ranking (eg ARC, Hellaswag, Lambada), some others do not provide a good signal for dataset comparison. Extreme case is MMLU (MCQ version), where most of datasets except Nemontron-cc lead to score close to random guessing, making differentiation hard.
Fig. 3 presents the performance across evals for the 3 best ranked datasets again training on 1.7B model scale, using larger token scale of 1T tokens. The ranking remains consistent, Nemotron staying mostly on the top followed or matched by DCLM and FineWeb-Edu (with exception of lambada), while performance is going up as expected when increasing token scale. MMLU still does not give sufficient signal on this model scale for DCLM and FineWeb-Edu, in contrast to Nemotron-CC-HQ. This highlights again that base model training can give the ability to handle instruction-like question formats, eg multiple choice question (MCQ) format used in MMLU, only when providing in the dataset mix instruction like samples, which is the case of Nemotron-CC-HQ, but not the case for DCLM and FineWeb-Edu.
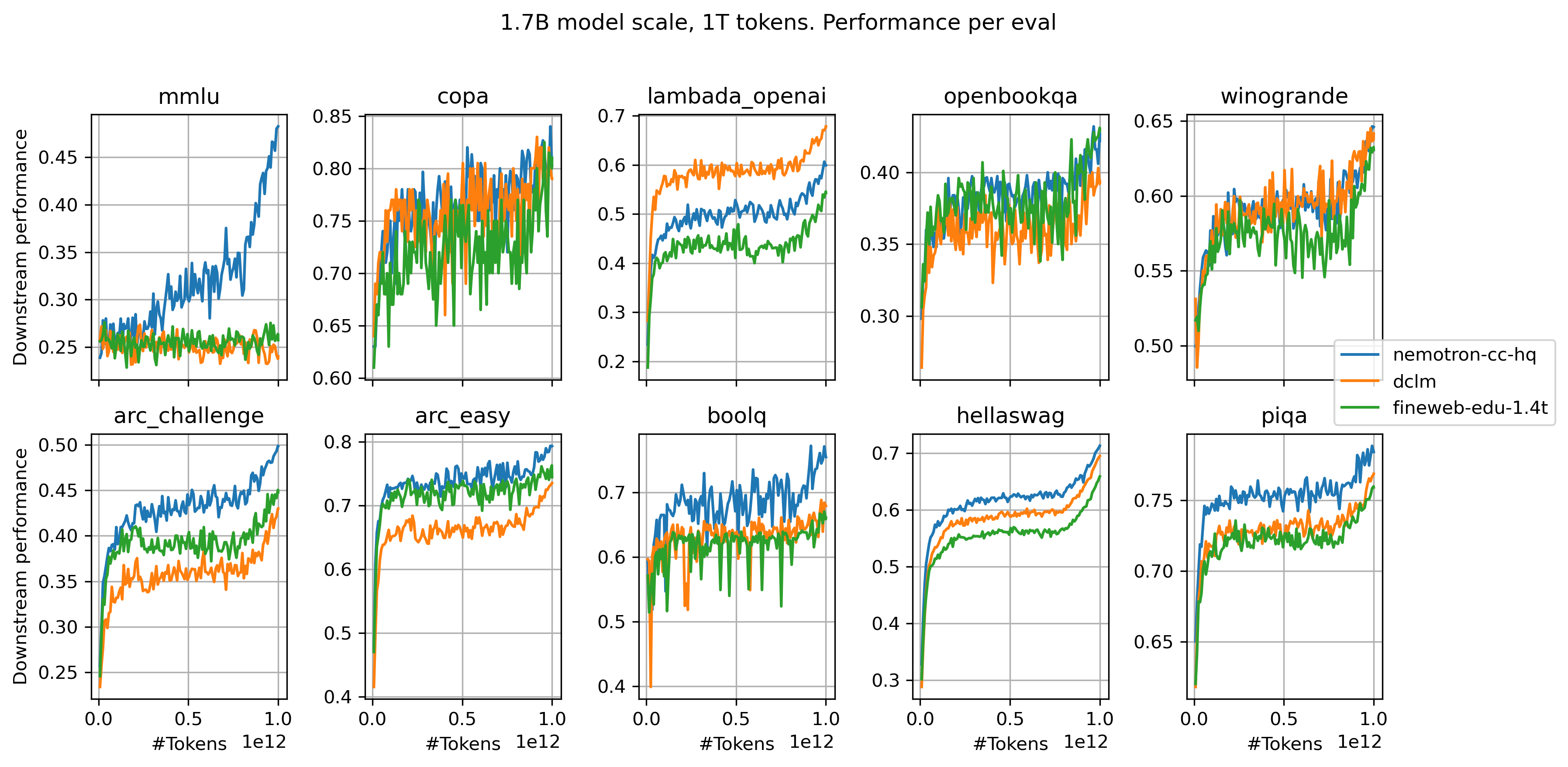
Figure 3: Comparing performance of 1.7B models trained on 3 top ranked reference datasets (Nemotron CC HQ, DCLM-baseline, FineWeb-Edu) for 1T tokens. Comparison shown on 10 different evals. Nemotron consistently occupies top ranking, with exception of lambada.
In Fig. 4, we show scaling behavior of our open-sci-ref reference baseline models when varying the training compute budget (increasing both model and token scale) for different datasets. This highlights that by performing measurements across selected reference scales, consistent dataset ranking can be established by looking at scaling trends across broad scaling span while aligning evaluated models on common compute axis. The scaling analysis can hint on promising strong datasets even given a low training budget setting and without deriving full scaling laws. For more accurate predictions and candidate dataset comparison, full scaling law derivation is required which relies on more dense measurements that performed in this study. Such measurements can identify points that are close to compute optimal Pareto front. In contrast, simple scaling trends presented here take model points that can be far away from compute optimal Pareto front (eg., large under-trained, small overtrained, or models with badly tuned hyperparams), so that we have to be careful when making conclusions from trends indicated by drawing lines through such points, as we will discuss below.
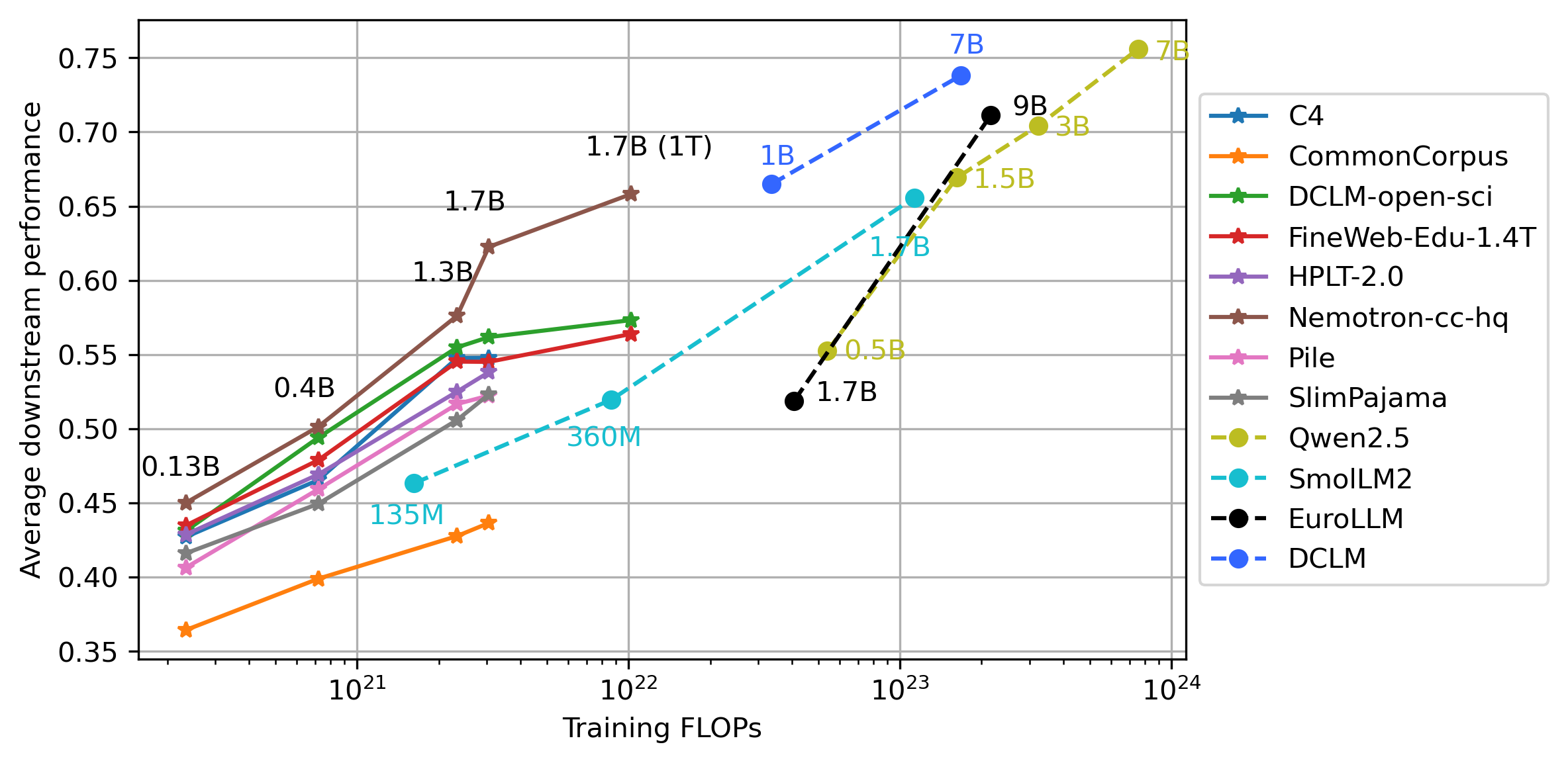
Figure 4: Scaling trends: open-sci-ref reference baselines (0.13, 0.4, 1.3, 1.7B model scales and 300B, 1T token scales) using 8 different datasets (solid lines) compared to other models (SmolLM2, Qwen 2.5, EuroLLM, DCLM) across various model and token scales (dashed lines), aligned on common compute axis (all tested models are base models). Evaluating reference baselines that use the same training procedure across scales while accounting for training compute provides dataset comparison and ranking. Nemotron-CC-HQ, DCLM and FineWeb-Edu are strong reference datasets leading the ranking.
To provide reference baselines at larger scales, we also release checkpoints trained on 1T tokens and report their average and per eval performance on Tab. 5, providing comparison with models of similar sizes (1.7B) and similar or different total token budgets, resulting in similar or different total compute in the pre-training. Interestingly, our reference baseline 1.7B model trained on Nemotron-cc HQ for 1T token matches SmolLM2-1.7B (both 0.66 average score), achieving competitive results despite being trained on a much smaller number of tokens (1T vs 11T), using thus much less (11x) compute. This is noteworthy, in particular given that we use a very simple single stage pipeline that does not change dataset mixture during different stages in pre-training or performs annealing mixing in further high-quality specialized data. This shows again that strong datasets like Nemotron-CC HQ are decisive for training quality and can enable strong models obtained in much more efficient manner with less data and less compute required for the given target quality than weaker datasets can deliver. As a reminder, our reference baselines are there to enable model and dataset comparison, and despite observed strong performance on standardized benchmarks should not be considered as competitors with current state-of-the-art models like SmolLM2/3, DCLM 1B, 7B or Qwen 2.5/3, which, apart from using substantially more compute, also use mixtures of further high quality math and code data for multi-stage training that are not used in our reference baseline training experiments.
| Model | Dataset | Tokens | Params (B) |
Compute (FLOPS) |
Avg | copa [0] |
lambada [0] |
open bookqa[0] |
wino grnd[0] |
mmlu [5] |
arc-c [10] |
arc-e [10] |
boolq [10] |
common sense[10] |
hellaswag [10] |
piqa [10] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gemma-2-2b | -- | 2.0T | 2.60 | 3.12 × 1022 | 0.68 | 0.88 | 0.70 | 0.37 | 0.69 | 0.53 | 0.52 | 0.82 | 0.80 | 0.65 | 0.74 | 0.80 |
| Qwen2.5-1.5B | -- | 18.0T | 1.50 | 1.62 × 1023 | 0.67 | 0.83 | 0.62 | 0.36 | 0.63 | 0.61 | 0.52 | 0.81 | 0.78 | 0.76 | 0.68 | 0.77 |
| DCLM-1B | DCLM | 4.0T | 1.40 | 3.36 × 1022 | 0.66 | 0.90 | 0.67 | 0.43 | 0.68 | 0.47 | 0.48 | 0.78 | 0.75 | 0.62 | 0.74 | 0.79 |
| SmolLM2-1.7B | smolLM2 | 11.0T | 1.70 | 1.13 × 1023 | 0.66 | 0.82 | 0.67 | 0.38 | 0.66 | 0.50 | 0.52 | 0.80 | 0.75 | 0.60 | 0.73 | 0.78 |
| open-sci-ref-1.7B | Nemotron | 1T | 1.70 | 1.02 × 1022 | 0.66 | 0.84 | 0.60 | 0.43 | 0.63 | 0.50 | 0.51 | 0.80 | 0.79 | 0.62 | 0.72 | 0.79 |
| open-sci-ref-1.7B | DCLM | 1T | 1.70 | 1.02 × 1022 | 0.57 | 0.79 | 0.68 | 0.40 | 0.64 | 0.24 | 0.44 | 0.76 | 0.69 | 0.19 | 0.70 | 0.77 |
| open-sci-ref-1.7B | FineWeb-Edu | 1T | 1.70 | 1.02 × 1022 | 0.56 | 0.81 | 0.54 | 0.43 | 0.63 | 0.26 | 0.47 | 0.76 | 0.67 | 0.20 | 0.67 | 0.76 |
| open-sci-ref-1.7B | FineWeb-Edu | 300B | 1.70 | 3.06 × 1021 | 0.55 | 0.76 | 0.52 | 0.42 | 0.61 | 0.26 | 0.44 | 0.75 | 0.67 | 0.19 | 0.63 | 0.76 |
| HF-ref-1.7B | FineWeb-Edu | 350B | 1.70 | 3.57 × 1021 | 0.54 | 0.78 | 0.50 | 0.37 | 0.58 | 0.25 | 0.46 | 0.77 | 0.66 | 0.19 | 0.62 | 0.75 |
| EuroLLM-1.7B | -- | 4.0T | 1.70 | 4.08 × 1022 | 0.52 | 0.74 | 0.53 | 0.33 | 0.59 | 0.27 | 0.39 | 0.73 | 0.61 | 0.19 | 0.60 | 0.74 |
Table 5: Performance on various evals of our reference models trained on 1T tokens on Nemotron-cc-hq, DCLM, FineWeb-Edu (also for 300B tokens) and as well as several other baselines. Models are sorted by their average eval performance. HF-ref model is reference training run of 1.7B scale released by HuggingFace in the frame of their FineWeb study using 350B tokens. [n] for evaluation tasks indicate the number of shots. open-sci-ref 1.7B trained in Nemotron 1T tokens is a strong reference baseline, closely matching smolLM2 which uses 11x more compute, pointing to Nemotron-cc-hq as strong reference training dataset.
As an example of insights that can be drawn from such comparisons, we obtain evidence from comparison of open-sci-ref-1.7B trained on FineWeb-Edu for 1T and 300B tokens with EuroLLM-1.7B that multilingual training is still a challenge. We take EuroLLM for comparison as it represents so far the strongest multi-lingual model coming from EU based efforts, outpeforming significantly similar motivated EU based models like Salamandra, openGPT-X or Occiglot. EuroLLM-1.7B used FineWeb-Edu as core part of its pre-training dataset, having at least 50% english data while adding multiple languages to reach total of 4T tokens, making it an interesting case for comparison. We observe that EuroLLM-1.7B underperforms across all english benchmarks open-sci-ref-1.7B trained on 1T tokens of FineWeb-Edu data, and even on 300B tokens of FineWeb-Edu, open-sci-ref-1.7B still prevails on many benchmarks. This shows that mixing languages can lead to strongly diminished problem solving performance, even if using substantially more compute for English (2x in case of EuroLLM).
In general, aligning models on the common compute axis for evaluation as done in Fig. 4 and Tab. 5 can provide a good overview where various learning procedures stand relative to each other, which is often difficult if not making compute that went into the training explicit. Again, for EuroLLM 1.7B we see that for its model scale and invested compute, it strongly underperforms other learning procedures. Eg, it has same performance level as SmolLM2 360M which has smaller model scale and used substantially less compute, also matching or underperforming 1.7B open-sci-ref models that used less compute. DCLM-1B model that has slightly less compute than EuroLLM 1.7B strongly outperforms it. It is therefore important to not take the slopes of the scaling trends as indication how scalable the learning procedure is, without comparing the points to other reference procedures. Points on smaller scales that are highly suboptimal can create the illusion of a strongly scalable learning procedure by making the slope very steep. Proper scaling trend estimation requires the models across scales to be close to compute optimal. Such measurements are executed for scaling law derivation, which identifies models trained close to compute optimal Pareto front and gives thus much more accurate predictions about learning procedure behavior than scaling trends presented here, however requiring more dense measurements and hyperparameter tuning effort.
Scaling trends based on suboptimal points can still reveal model families with similar learning procedures that lead to similar strong performance, as those show similar trends across scales and closely match performance for a given compute. Eg, smolLM2 scaling trend is smoothly continued by Qwen 2.5 at larger scales, the smolLM2 1.7B and Qwen 2.5 1.5B also residing close to each other in compute and eval performance. In contrast, there is clear mismatch between EuroLLM 1.7B and Qwen 2.5 0.5B that are close in compute and performance, but have different model scale, indicating strong advantage of learning procedure behind Qwen over EuroLLM. DCLM also shows strong scaling trend, as seen by 1B model matching performance of Qwen 1.5B model despite less compute, and 7B model almost matching Qwen 7B, again despite less compute. In contrast, EuroLLM 9B is outperformed by DCLM 7B, despite having slightly more compute and larger model scale, being also on the same level with Qwen 3B, which has much smaller model scale and similar compute, again indicating EuroLLM training being suboptimal. We see that open-sci-ref trained on Nemotron might match the DCLM trend if continuing to increase compute, despite open-sci-ref training procedure having single stage only without dataset mixture changes, again indicating that Nemotron is a strong dataset for training. We see thus how aligning trained models on common compute axes can help to identify strengths and weaknesses of learning procedures, and also how important it is to have comparison to existing reference baselines evaluated in the same controlled frame.
Another interesting insight from comparisons to our reference baselines can be drawn from the level of performance we measure on multilingual problem solving benchmark MMLU (Fig. 5). Despite being pre-trained only on Nemotron-CC-HQ, a largely english dominated dataset, open-sci-ref shows stronger performance in language understanding problem solving on multi-lingual MMLU than EuroLLM-1.7B across multiple languages which were explicitly included into training set for EuroLLM, which also has larger compute budget in pre-training overall (ca. 4x open-sci-ref). This demonstrates that English only pre-training enables language comprehension and problem solving across multiple languages if dataset composition is strong like in case with Nemotron-CC-HQ. It also shows again that composition of multilingual dataset mixtures is a difficult open question, given the evidence of diminished problem solving capability shown by EuroLLM that underperforms in problem solving across various languages, despite explicit inclusion of languages used in the test benchmarks and using more compute during pre-training, in comparison to reference baselines that were trained on strong english only data. Again, this demonstrates the central role of the dataset composition for obtaining high quality pre-training. It is important to note that multilingual problem solving capability and multi-lingual language generation are two independent skills. Reference baseline models show substantial problem solving capability in multilingual setting, at the same time they are still english dominant models and will expectedly perform poorly in language generation tasks apart from english setting, eg not being able to generate proper natural language flow in Finnish as opposed to english.
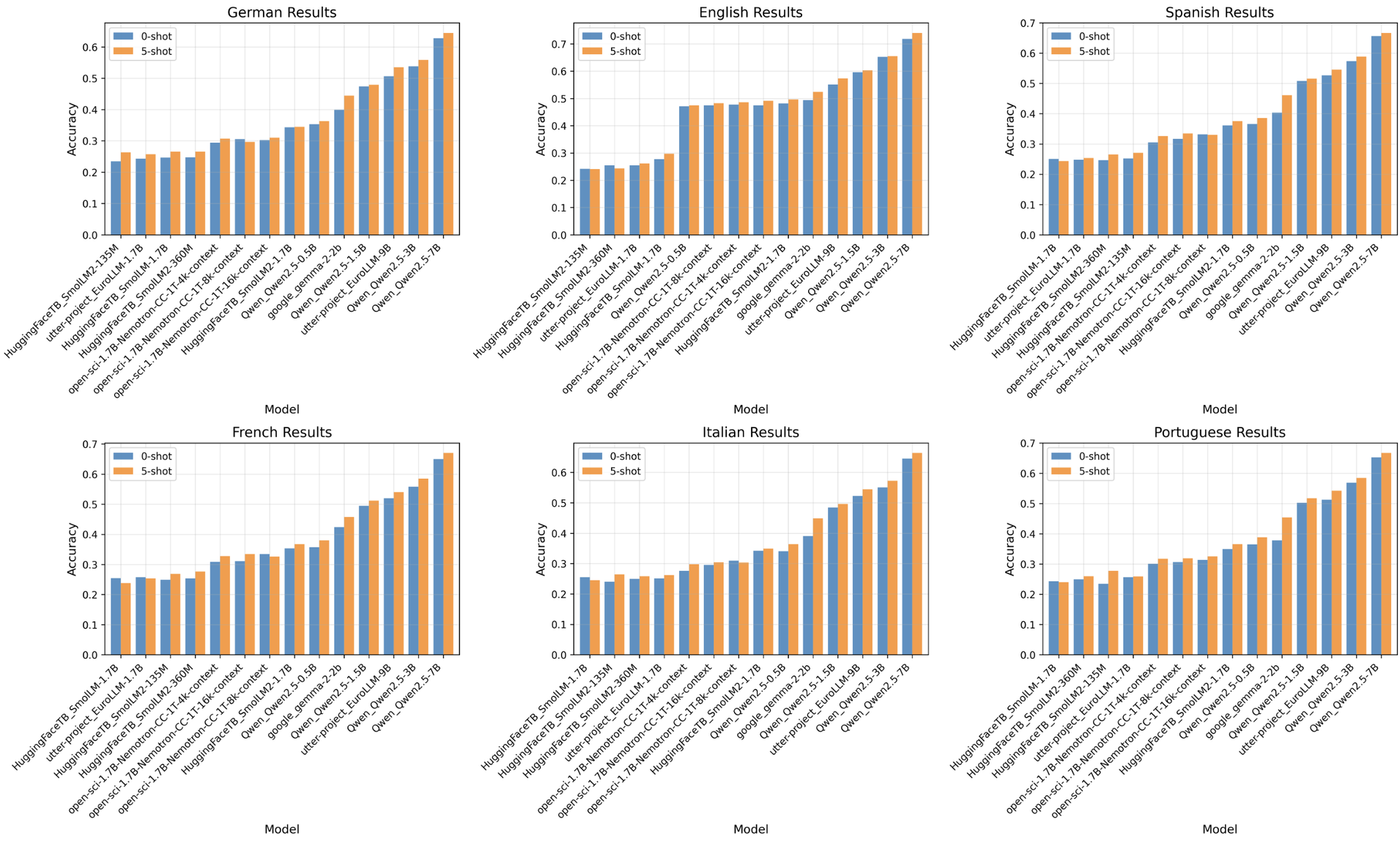 Figure 5: Performance of English pre-trained open-sci-ref on MMMLU, which is a version of MMLU benchmark translated to multiple languages by OpenAI employing human professional translators.
Figure 5: Performance of English pre-trained open-sci-ref on MMMLU, which is a version of MMLU benchmark translated to multiple languages by OpenAI employing human professional translators.
Further reference baselines
Learning rate schedules. To make sure that reference training shows similar performance when executed with various schedules, we check training with cosine schedule to match close constant learning rate and cooldown schedule (also known as warmup, stable, decay, WSD, or trapezoid schedule). We execute baseline training on C4 dataset with 50B tokens, using both cosine and WSD schedule, tuning hyperparameters for each schedule (see Tab. 2 and Tab. 3). We see matching performance for cosine and WSD on downstream evals. The learning rate for WSD is roughly $2/3$ of the learning rate for cosine.
Context length. We also perform training with various context lengths while making sure that the global batch size remains constant across different variants. We train 2048, 4096, 8192 and 16384 context length, and observe no difference on downstream evals. When varying context length, we also adapt base for RoPE correspondingly (10k for 2048 and 4096, 100k as alternative for 4096, 500k for 8192 and 1M for 16384).
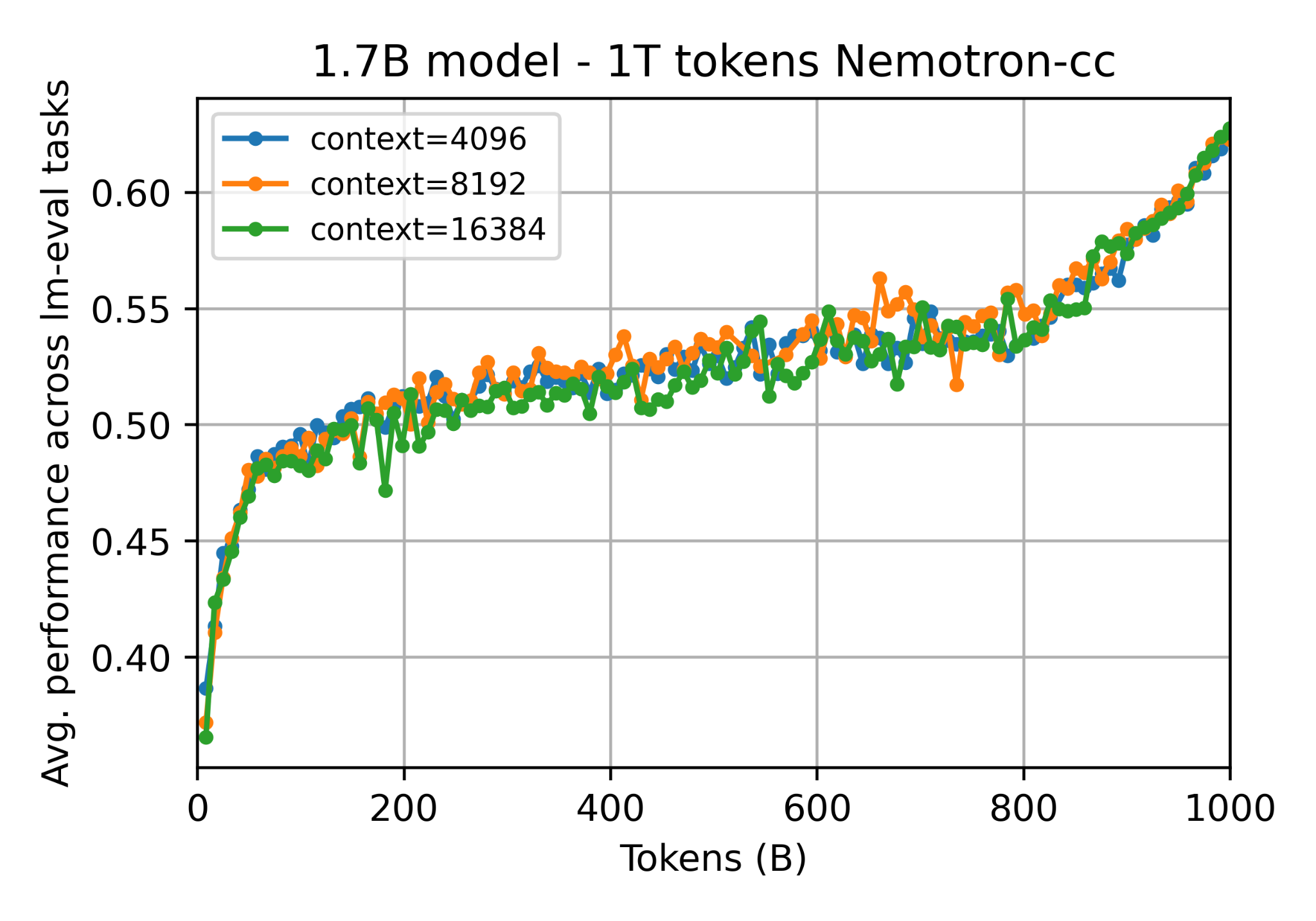 Figure 6: Comparing training with different context length. Training run for open-sci-ref 1.7B model on 1T token of Nemotron-CC-HQ, using various context length of 4096 (RoPE base 100k), 8192 (RoPE base 500k) and 16384 (RoPE base 1M). We observe no difference in average performance, ensuring models with larger context length have no drop in performance compared to reference context length of 4096.
Figure 6: Comparing training with different context length. Training run for open-sci-ref 1.7B model on 1T token of Nemotron-CC-HQ, using various context length of 4096 (RoPE base 100k), 8192 (RoPE base 500k) and 16384 (RoPE base 1M). We observe no difference in average performance, ensuring models with larger context length have no drop in performance compared to reference context length of 4096.
Dropout. We also perform a test enabling or disabling dropout (hidden and attention), without observing any relevant difference in performance (the released models have dropout=0.1).
Distributed training on supercomputers
We make use of various publicly funded European supercomputers to perform distributed training necessary for obtaining reference models. We conducted training experiments using Megatron-LM (hash 31a29b87 via git rev-parse --short HEAD), employing NVIDIA containers for each machine. We used Leonardo (CINECA, 64GB A100), JUWELS Booster (JSC, 40GB A100), JEDI (JSC, early JUPITER prototype, 96GB H100) and JUPITER (JSC, 96GB H100). For each model scale, a combination of GPU numbers was selected that was providing good throughput and GPU utilization given the global batch size. We obtain good GPU utilization of 150-200 TFLOPS/s/GPU on A100 machines and 320-400 TFLOPS/s/GPU on H100 machines while working with hundreds of GPUs. As the model scales are still small, we could execute training efficiently with standard data parallelism only (TP=PP=1, no FSDP). See the Tab. 5, 6, 7, 8 for the distributed training run characteristics.
| Model (B) |
GPUs | micro bs | context length |
global bs (smpl/token) |
TFLOPS/GPU/s | Tokens/GPU/s | Run Time, h (50B/300B/1T) |
GPU A100 h (50B/300B/1T) |
|---|---|---|---|---|---|---|---|---|
| 0.13 | 84 | 12 | 4096 | 1008/4.12M | 114 | 87710 | 1.89/11.31/37.70 | 158/950/3167 |
| 0.4 | 100 | 10 | 4096 | 1000/4.09M | 157 | 44550 | 3.12/18.71/62.35 | 312/1871/6235 |
| 1.3 | 252 | 4 | 4096 | 1008/4.12M | 172 | 16800 | 3.28/19.68/65.60 | 827/4959/16530 |
| 1.7 | 216 | 6 | 2048 | 1296/2.65M | 167 | 18490 | 3.48/20.87/69.56 | 751/4508/15026 |
| 1.7 | 252 | 4 | 4096 | 1008/4.12M | 184 | 14490 | 3.80/22.81/76.05 | 958/5749/19164 |
| 1.7 | 252 | 2 | 8192 | 504/4.12M | 186 | 12320 | 4.47/26.84/89.47 | 1127/6764/22546 |
| 1.7 | 252 | 1 | 16384 | 252/4.12M | 201 | 10080 | 5.47/32.80/109.32 | 1377/8265/27549 |
Table 5: Open-sci-ref reference baseline distributed training runs on Leonardo.
| Model (B) | GPUs | micro bs | context length |
global bs (smpl/token) |
TFLOPS/GPU/s | Tokens/GPU/s | Run Time, h (50B/300B/1T) |
GPU A100 h (50B/300B/1T) |
|---|---|---|---|---|---|---|---|---|
| 1.3 | 328 | 6 | 2048 | 1968/4.03M | 158 | 17400 | 2.43/14.60/48.66 | 798/4788/15961 |
Table 6: Open-sci-ref reference baseline distributed training runs on JUWELS Booster.
| Model (B) | GPUs | micro bs | context length |
global bs (smpl/token) |
TFLOPS/GPU/s | Tokens/GPU/s | Run Time, h (50B/300B/1T) |
GPU H100 h (50B/300B/1T) |
|---|---|---|---|---|---|---|---|---|
| 1.3 | 64 | 16 | 2048 | 1024/2.09M | 320 | 35370 | 6.13/36.81/122.70 | 393/2356/7853 |
| 1.7 | 128 | 2 | 16384 | 256/4.19M | 395 | 19820 | 5.48/32.85/109.50 | 701/4205/14016 |
Table 7: Open-sci-ref reference baseline distributed training runs on JEDI.
| Model (B) | GPUs | micro bs | context length |
global bs (smpl/token) |
TFLOPS/GPU/s | Tokens/GPU/s | Run Time, h (50B/300B/1T) |
GPU H100 h (50B/300B/1T) |
|---|---|---|---|---|---|---|---|---|
| 1.7 | 128 | 8 | 4096 | 1024/4.19M | 370 | 29170 | 3.72/22.32/74.39 | 476/2856/9521 |
Table 8: Open-sci-ref reference baseline distributed training runs on JUPITER.
Releasing artifacts
For each reference baseline, we release full training artifacts, including final open-weights models for each dataset and intermediate checkpoints during the training, together with logs and training workflow source code. This should enable comparison across open reference datasets we have used, both at the end of training and also at any intermediate state during the training. This also allows studying training dynamics on different open datasets. Releasing the reference models trained on openly accessible datasets on multiple scales - 135M, 400M, 1.3B, 1.7B in model parameters and 50B, 300B and 1T tokens in terms of data scales - provides for the research community a reference frame to compare their procedures on a broad scale span across datasets, instead of taking for comparison only one fixed scale on one dataset only.
We release models and intermediate checkpoints via HugginFace open-sci-ref collection.
We provide an overview of all the released artifacts and further infos for reproducing training and evaluation at open-sci-ref-0.01 release repository, which will be continuously updated.
Conclusion and outlook
With open-sci-ref-0.01 research release, we provide set of dense transformer models on 0.13B-0.4B-1.3B-1.7B scales trained on important reference datasets C4, Pile, SlimPajama, FineWeb-Edu-1.4T, DCLM-Baseline and NemoTron-CC-HQ, including two further relevant datasets HPLT-2.0 and CommonCorpus, for token budgets of 50B, 300B and 1T. These reference models provide baselines for comparison to any other method trained on any of the same reference open datasets, making it easier to put a new training procedure into relation to already existing working baselines. We also release all intermediate checkpoints and logs from each reference training, which supports studies on learning dynamics and learning interventions on different phases of training. As we use a constant learning rate schedule, intermediate checkpoints can be studied either by continuing training or by cooling down from any point in the training procedure.
While this research release mainly aims on establishing baselines for sanity checks and comparison to other procedures, we also deliver valuable insights into the quality of important reference datasets. The dataset rankings we obtain are robust as they are established through both the training evolution and behavior at various scales, this provides a much more robust ranking than comparison based on measurements conducted on only one fixed scale. Establishing comparisons that are valid across broad scales span remains an open challenge and will require the derivation of full scaling laws (as performed for instance in Nezhurina et al, 2025) and is subject of follow up work.
Having established reference baselines that can be used for comparison to any other learning procedure, in the upcoming work we will have a look at a) datasets with permissively licensed data to compare those to reference datasets which contain non-permissive data b) architectures like MoE to compare those to dense transformers c) conducting measurements for full scaling law derivation to use for the comparison of learning procedures. The established reference baselines and comparisons to those will also help us to conduct guided search for stronger scaling learning procedures to improve current state-of-the-art. This will be also important in the frame of further collaborative projects like EU openEuroLLM which will benefit from working with the already established common reference frame while experimenting with various interventions to the reference learning procedure, for instance to enable multi-lingual training that does not diminish model core capabilities as often observed in the drop on english based benchmarks.
Contributors
Marianna Nezhurina: established major part of dataset processing (tokenization) and training infrastructure (Megatron-LM container based workflow), conducted scaling tests for distributed training, wrote routines for evaluation based on lm-eval-harness, downloaded and tokenized datasets, co-designed experiments, converted DCLM base models (1B, 7B) to HF and ran evaluation for the scaling plot. Co-wrote code for tables and figures.
Joerg Franke: downloaded and tokenized datasets, transferred datasets between various machines, co-designed experiments, conducted training experiments.
Taishi Nakamura: wrote checkpoint conversion routines from Megatron to HuggingFace format for custom open-sci-ref models to enable easy evaluation via lm-eval-harness.
Timur Carstensen: automated and performed conversion of all the Megatron checkpoints to HuggingFace format for evaluation using a script provided by Marianna and Taishi, helped running evaluations, provided the tooling to parse all hyperparameters from the logs, performed the evaluations and visualizations on MMMLU.
Niccolò Ajroldi: helped running evaluations and fixed a bug in lm-eval-harness to handle custom paths.
Ville Komulainen: uploaded all the intermediate and final checkpoints to HuggingFace, co-organized HuggingFace repository.
David Salinas: wrote the infrastructure to automate and perform large batch of evaluations, ran most of the evaluations, wrote code to generate most of the tables and figures except for MMMLU, co-wrote the blog post.
Jenia Jitsev: coordination and project supervision; acquired compute resources; designed the experiments (scales, architecture configuration, evaluation selection), wrote training scripts for various supercomputers, conducted major fraction of training runs, wrote routines for transferring datasets across supercomputers, downloaded and transferred the datasets across the machines, helped running evaluation, composed tables and figures, wrote the blog post.
Citation
If you like this work, please cite:
@article{opensciref001arxiv, title={Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison}, author={Nezhurina, Marianna and Franke, Joerg and Nakamura, Taishi and Carstensen, Timur and Ajroldi, Niccol{`o} and Komulainen, Ville and Salinas, David and Jitsev, Jenia}, journal={arXiv:2509.09009}, year={2025} }
@misc{opensciref001blog,
author = {Nezhurina, Marianna and Franke, Joerg and Nakamura, Taishi, and Carstensen, Timur, and Ajroldi, Niccolò and Komulainen, Ville, and Salinas, David and Jitsev, Jenia},
title = {{Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison}},
howpublished = {https://laion.ai/blog/open-sci-ref-001},
year = {2025}
}
Acknowledgments
MN, JF, TC, NA, VK and JJ acknowledge co-funding by EU from Digital Europe Programme under grant no. 101195233 (openEuroLLM). MN and JJ acknowledge co-funding from EuroHPC Joint Undertaking programme under grant no. 101182737 (MINERVA), as well as funding by the Federal Ministry of Education and Research of Germany (BMBF) under grant no. 01IS24085C (OPENHAFM), under the grant 16HPC117K (MINERVA) and under the grant no. 01IS22094B (WestAI - AI Service Center West).
We gratefully acknowledge the Gauss Centre for Supercomputing e.V. for funding this work by providing computing time through the John von Neumann Institute for Computing (NIC) on the supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC), EuroHPC Joint Undertaking for computing time and storage on the EuroHPC supercomputer LEONARDO, hosted by CINECA (Italy) and the LEONARDO consortium through an EuroHPC Extreme Access grant EHPC-EXT-2023E02-068, storage resources on JUST granted and operated by JSC and supported by Helmholtz Data Federation (HDF), computing time granted by the JARA and JSC on the supercomputer JURECA at JSC, and computing time granted on prototype JEDI via JUREAP (JUPITER Early Access Program) grant at JSC.
Further thanks go to support provided by supercomputing facilities and their teams, especially to Damian Alvarez and Mathis Bode from Juelich Supercomputer Center (JSC, Germany) and to Laura Morselli from CINECA (Italy).
We thank further for support & advising: Sampo Pyysalo, Guilherme Penedo, Quentin Anthony, Hynek Kydlíček, Mehdi Cherti, Tomer Porian, Adam Ibrahim, Jonathan Burdge, Aaron Klein, Ken Tsui, Harsh Raj, Huu Nguyen
We also would like to express gratitude to all the people who are working on making code, models and data publicly available, advancing community based research and making research more reproducible. Specifically, we would like to thank all the members of the Open-$\Psi$ (Open-Sci) Collective, openEuroLLM Consortium and LAION Discord server community for providing fruitful ground for scientific exchange and open-source development.