GAME REASONING ARENA: INSIDE THE MIND OF AI: HOW LLMS THINK, STRATEGIZE, AND COMPETE IN REAL-TIME
by: Lucia Cipolina-Kun, Marianna Nezhurina, Jenia Jitsev, 04 Aug, 2025
Access
- Repository: https://github.com/SLAMPAI/game_reasoning_arena
- Documentation: Complete installation, usage, and extension guides available at Game Reasoning Arena Documentation
- Paper: Game Reasoning Arena: A Framework and Benchmark for Assessing Reasoning Capabilites of Large Language Models via Game Play
- Leaderboard: Game Reasoning Arena Leaderboard
TL;DR The first platform to expose AI's strategic DNA in action
Game Reasoning Arena is the first platform to capture AI's strategic thinking in real-time. LLMs battle in board games (Tic-Tac-Toe, Connect Four, Khun-Poker, etc.) while we record every reasoning step. Built on OpenSpiel with Ray parallelization, it supports multi-agent tournaments and provides deep analysis of how different models strategize, adapt, and compete. Key finding: larger models show more adaptive reasoning patterns, while smaller models commit early to fixed strategies.
Quick start with Google Colab
Click here to try Game Reasoning Arena in our Colab now!
Why Strategic Games Matter for AI Evaluation
Strategic games offer unique evaluation opportunities that traditional benchmarks cannot provide: genuine decision-making under uncertainty. When an LLM plays Tic-Tac-Toe, Connect Four, or Poker, it must:
- Analyze complex game states with multiple possible outcomes
- Reason about opponent behavior and predict future moves
- Balance short-term tactics with long-term strategic goals
- Handle incomplete information and make decisions under pressure
- Adapt strategies based on opponent responses
This creates an ideal testing environment for evaluating the strategic reasoning capabilities that will be crucial as LLMs become more integrated into decision-making roles across industries.
Key Features of Game Reasoning Arena
Multi-Agent Testing Framework
Game Reasoning Arena supports comprehensive competitive scenarios:
- LLM vs Random: Establish baseline performance against unpredictable opponents.
- LLM vs LLM: Direct strategic competitions between different language models.
- Cross-Provider Tournaments: Compare models from different providers within the same game.
Diverse Game Library
The framework includes a carefully selected set of games that test different aspects of strategic thinking:
tic_tac_toe- Classic spatial reasoning and tactical planningconnect_four- Long-term strategic positioning and pattern recognitionkuhn_poker- Hidden information, bluffing, and probabilistic reasoningprisoners_dilemma- Cooperation versus competition dynamicsmatching_pennies- Zero-sum game theory and randomization strategiesmatrix_rps- Rock-paper-scissors with matrix representationhex- Complex pathfinding and connection strategies on a hexagonal gridchess- Deep combinatorial reasoning, multi-phase planning, and tactical foresight
Each game challenges LLMs in unique ways, from spatial reasoning to probabilistic thinking to social dynamics.
Flexible Inference Architecture
The system allows researchers to mix different backends within the same experiment, enabling direct comparison between proprietary and open-source models, or between API-based and locally-hosted implementations.
LiteLLM Backend - Access to over 100 language models through APIs:
vLLM Backend - Local GPU inference.
It also supports Hugging Face backends.
Reasoning Traces: Understanding AI Decision-Making
A particularly valuable feature of Game Reasoning Arena is its automatic reasoning traces capability. This functionality captures not only what move an LLM made, but also the reasoning behind that decision.
Data Collection
For every move made by an LLM agent, Game Reasoning Arena automatically records:
- Board State: The exact game position when the decision was made
- Agent Reasoning: The LLM's complete thought process and explanation
- Action Context: The chosen move with full metadata and timing
- Decision Patterns: Categorized reasoning types and strategic approaches
Example Reasoning Trace
Here is an example of the reasoning traces captured during gameplay:
Reasoning Trace #1
----------------------------------------
Game: connect_four
Episode: 3, Turn: 5
Agent: litellm_groq/llama3-8b-8192
Action Chosen: 3
Board State at Decision Time:
. . . . . . .
. . . . . . .
. . x . . . .
. o x . . . .
o x o . . . .
x o x . . . .
Agent's Reasoning:
I need to block the opponent's potential win. They have
two pieces in column 2 and if I don't act now, they
could get three in a row vertically. Playing column 3
also gives me a chance to build my own threat
horizontally while staying defensive.
Timestamp: 2025-08-04 14:23:17
Analysis Tools
Game Reasoning Arena includes comprehensive analysis capabilities for reasoning traces:
- Reasoning Categorization: Automatically classifies thinking patterns (Positional, Blocking, Winning Logic, Opponent Modeling, etc.)
- Pattern Visualization: Word clouds showing common reasoning terms, pie charts of strategy types
- Performance Heatmaps: Visual maps showing move preferences and strategic tendencies
- Statistical Analysis: Quantitative measures of decision-making patterns
This provides researchers with tools for understanding how different LLMs approach strategic problems, what reasoning patterns correlate with success, and where current models have strategic limitations.
Distributed Computing and Scalability
Game Reasoning Arena supports large-scale experiments through distributed computing capabilities:
Ray Integration
- Parallel Episodes: Execute multiple games simultaneously across different cores
- Multi-Game Tournaments: Run complex tournament brackets in parallel
- Distributed LLM Inference: Efficiently batch and distribute model calls
- Real-time Monitoring: Ray dashboard for live experiment tracking
SLURM Cluster Support
Game Reasoning Arena integrates seamlessly with SLURM clusters, enabling researchers to conduct large-scale tournaments.
Monitoring and Visualization via Tensorboard
Game Reasoning Arena includes native TensorBoard integration for experiment monitoring:
- Real-time Metrics: Monitor win rates, reward progressions, and performance trends during gameplay
- Multi-Agent Comparison: Side-by-side visualization of different LLM strategies
- Performance Evolution: Track how agents perform over multiple episodes
Extensibility and Customization
Game Reasoning Arena's modular architecture facilitates easy extension by adding new games, adding new LLM providers and adding custom policies such as reinforcement learning policies.
Research Applications and Findings
Game Reasoning Arena has already enabled several interesting research observations:
- Strategic Specialization: Certain LLMs demonstrate strong tactical play but struggle with long-term strategic planning
- Reasoning Diversity: Different models exhibit distinct strategic approaches and decision-making patterns
- Cross-Game Learning: Some strategic insights transfer between games, while others remain game-specific
- Opponent Modeling: Varying capabilities in predicting and countering opponent strategies
- Decision Consistency: Different levels of adherence to strategic principles under pressure
Example Results
Our analysis reveals fascinating insights into how different LLMs approach strategic thinking. Here are some key visualizations from our experiments:
Reasoning Pattern Distribution Across Models

Distribution of reasoning types across all LLM models and games, showing distinct strategic thinking patterns.
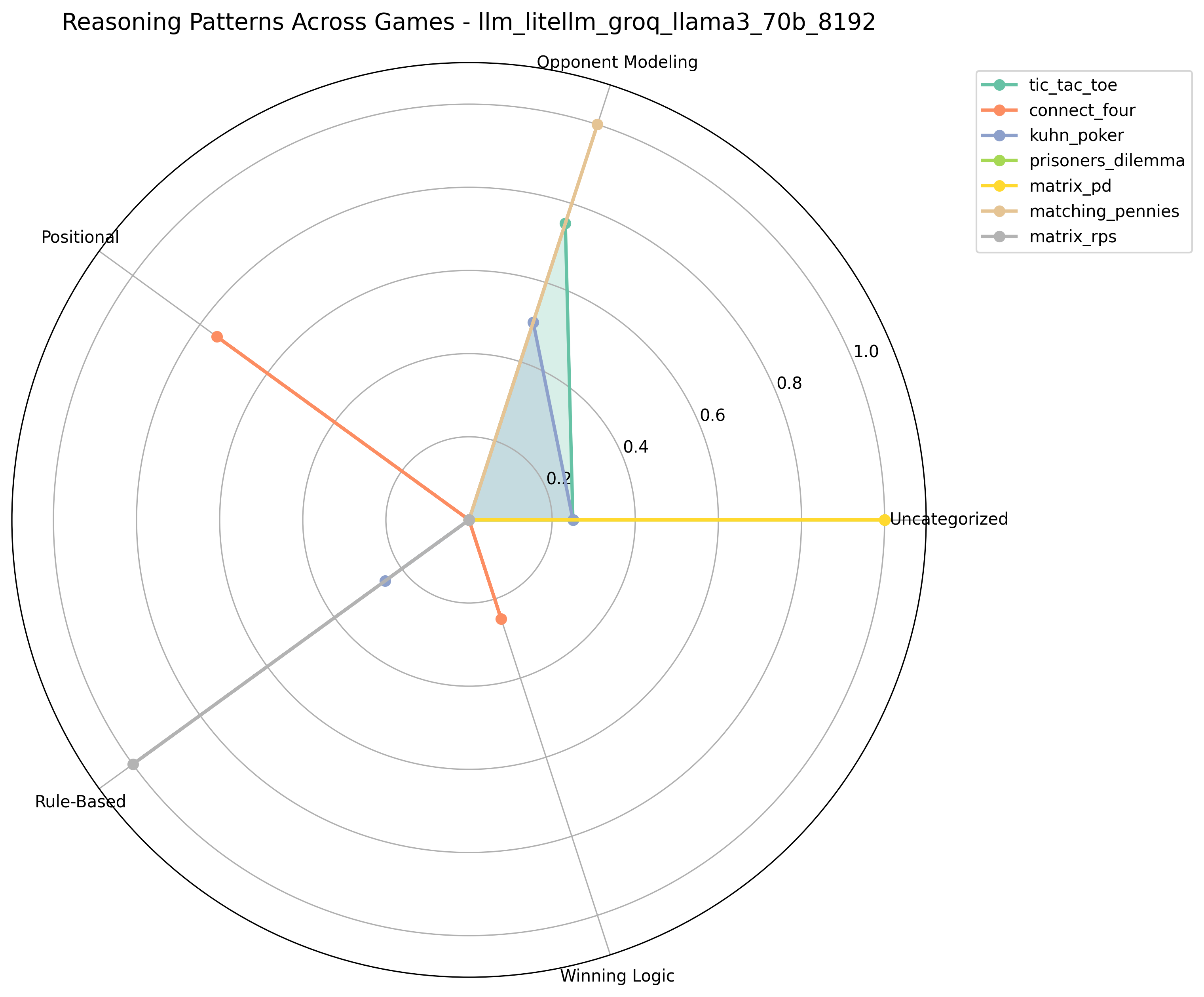
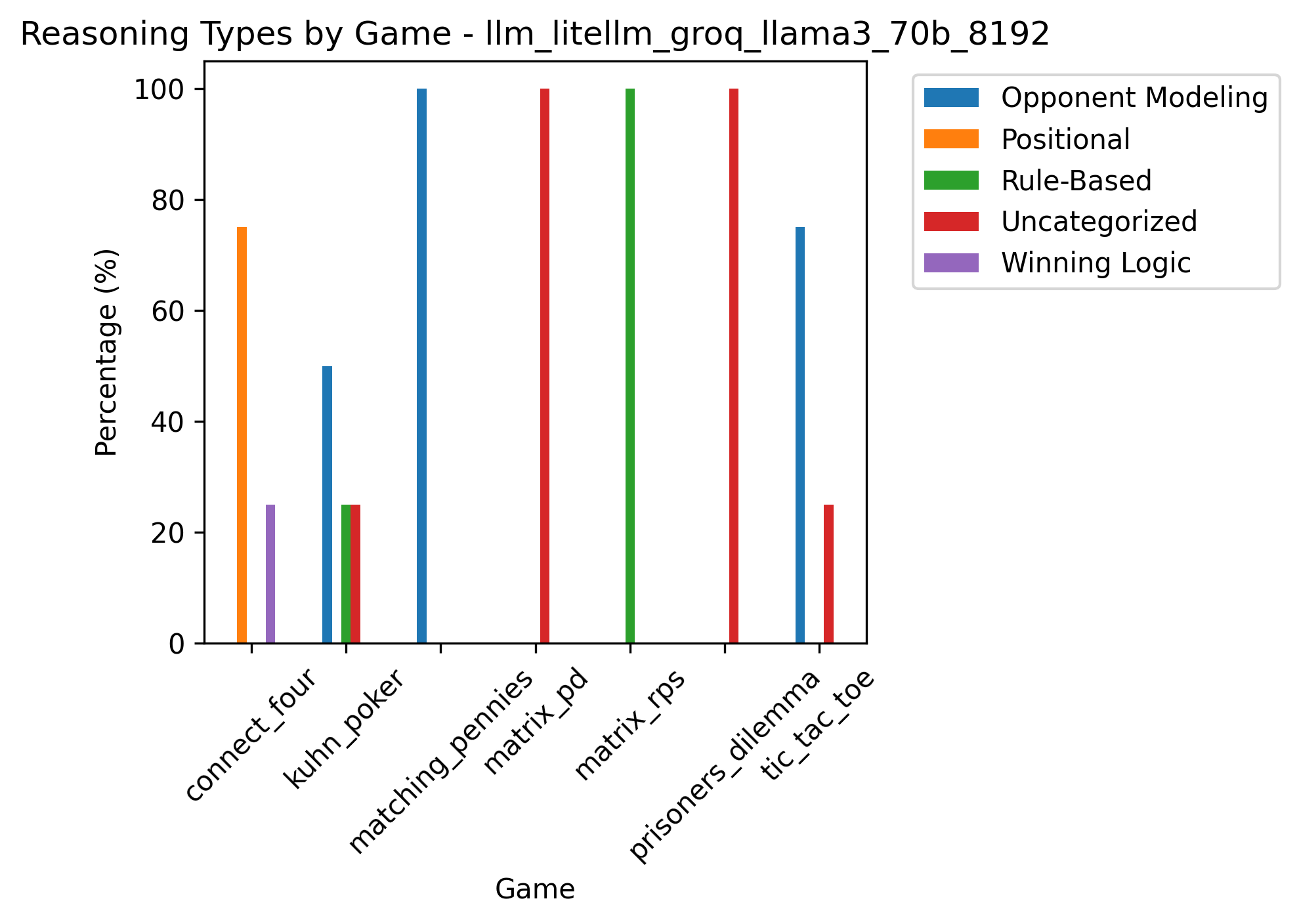
Radar plot showing the normalized distribution of reasoning types for each game played by Llama3 70B.
The radar chart reveals that Llama3 70B distributes its reasoning differently depending on the game context. For example, in Matching Pennies and Matrix PD, opponent modeling dominates, while Connect Four favors positional play. Rule-based reasoning emerges in Matrix RPS, showing that the model switches to more deterministic strategies when the game structure rewards fixed patterns.
Strategic Diversity in Different Games
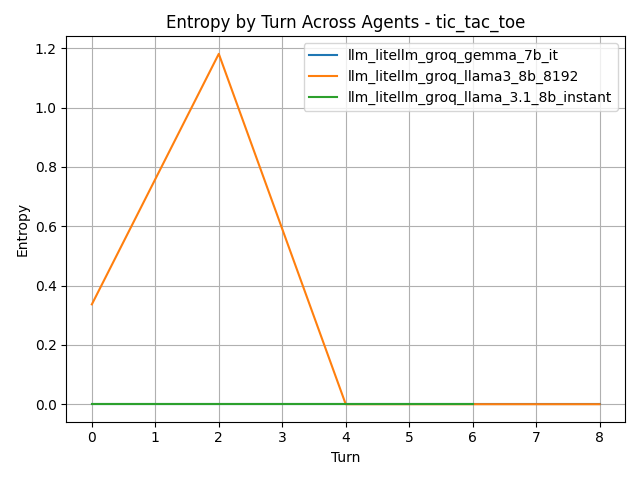
Entropy of reasoning distribution per turn for all agents in Tic-Tac-Toe.
While the first plot compares average diversity per game, the second shows per-turn changes.
Entropy measures the diversity of reasoning patterns at each turn. Here we see Llama3 8B spiking early in the game, suggesting exploration of different strategic avenues before quickly converging to a more fixed reasoning mode. In contrast, other models remain static, indicating a more rigid approach from the start.
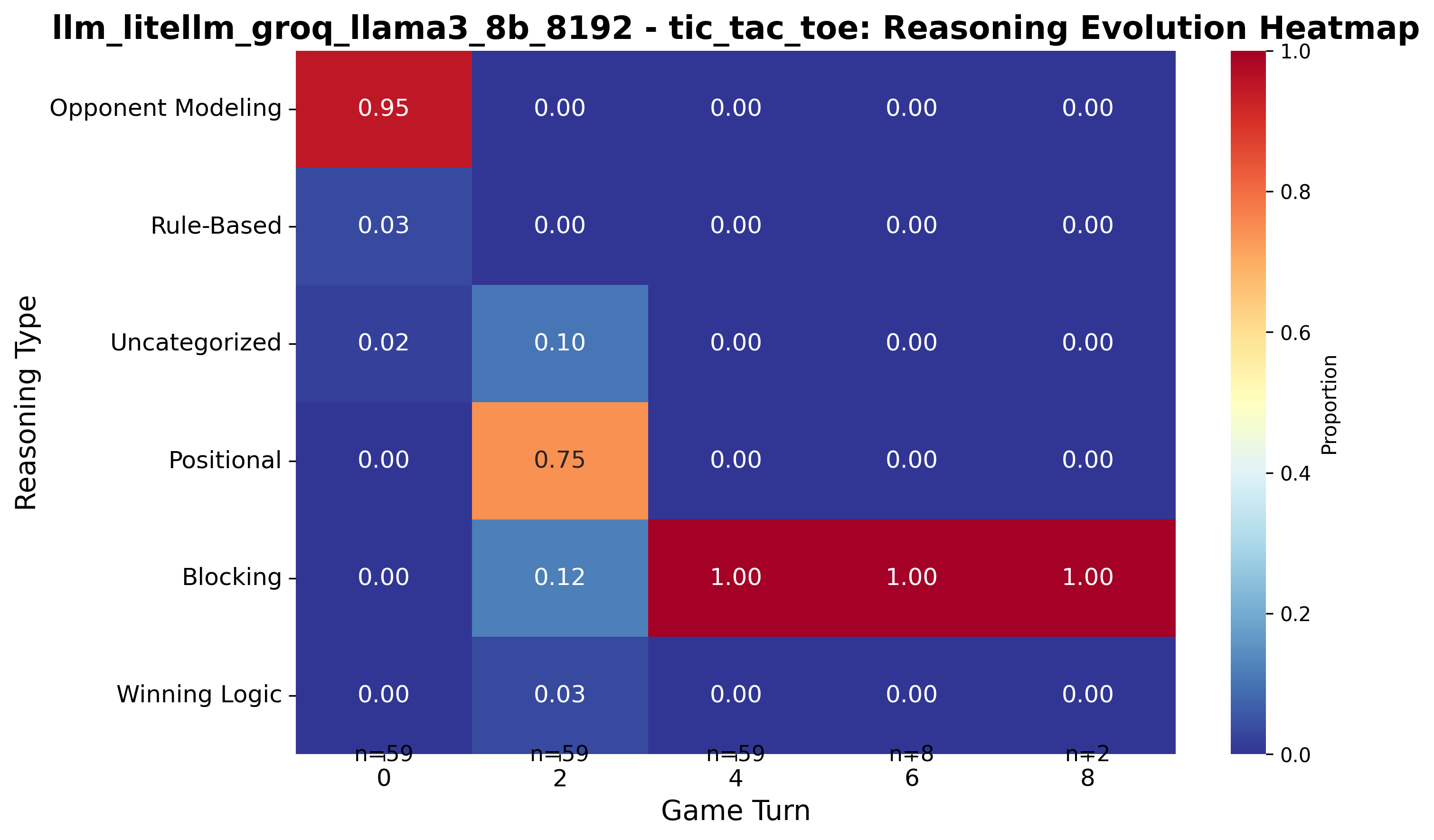
Evolution of Reasoning Patterns in Gameplay
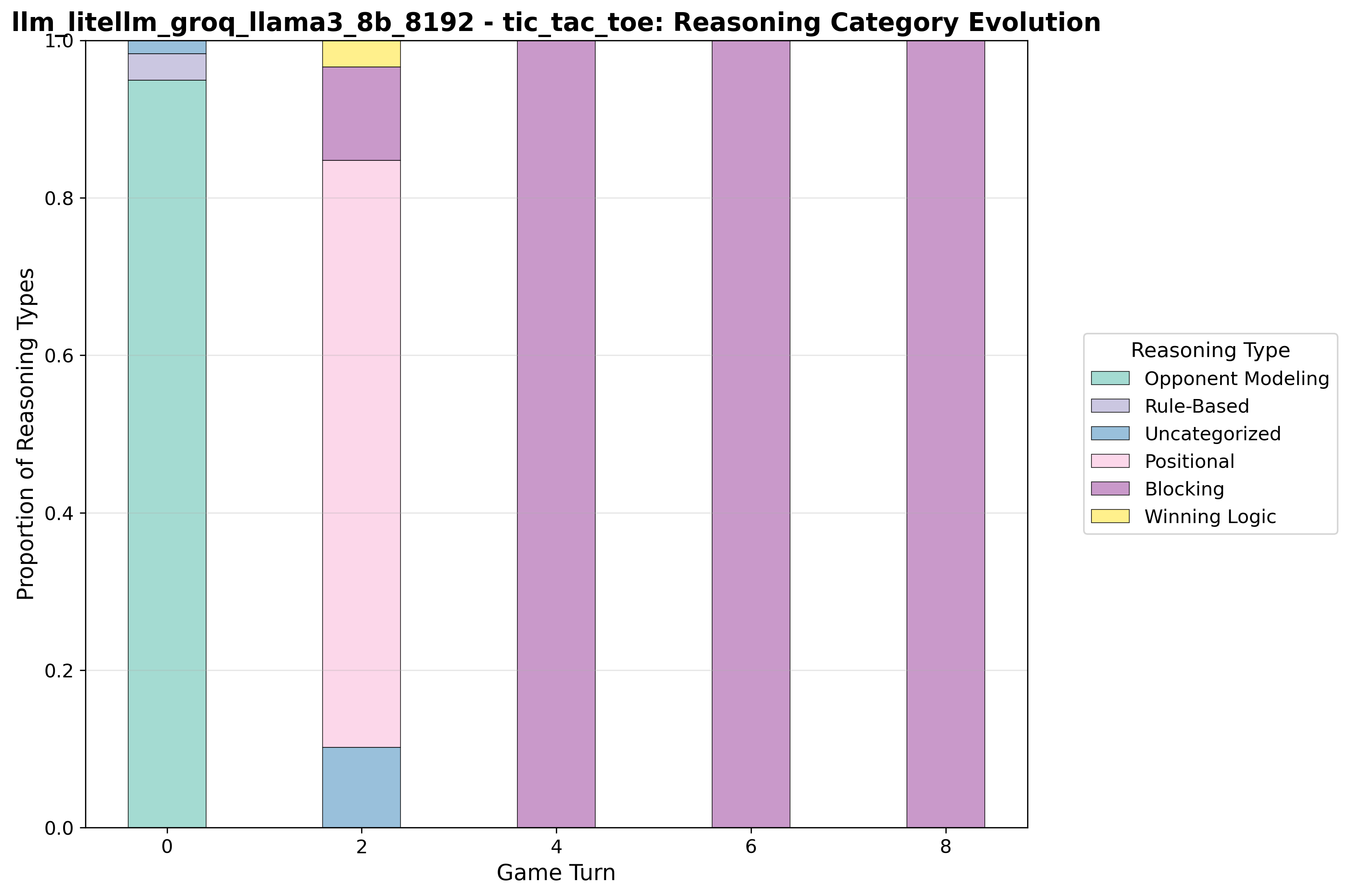
Proportion of reasoning categories as the game progresses. How Llama3 8B's reasoning patterns evolve during tic-tac-toe gameplay.
Llama3 8B starts with opponent modeling, shifts to positional play, then locks into blocking for the rest of the match. This suggests a defensive bias once the mid-game begins, perhaps prioritizing risk avoidance over creating winning opportunities.
Model-Specific Strategic Reasoning Across all Games
Aggregation of strategic decisions across all games.
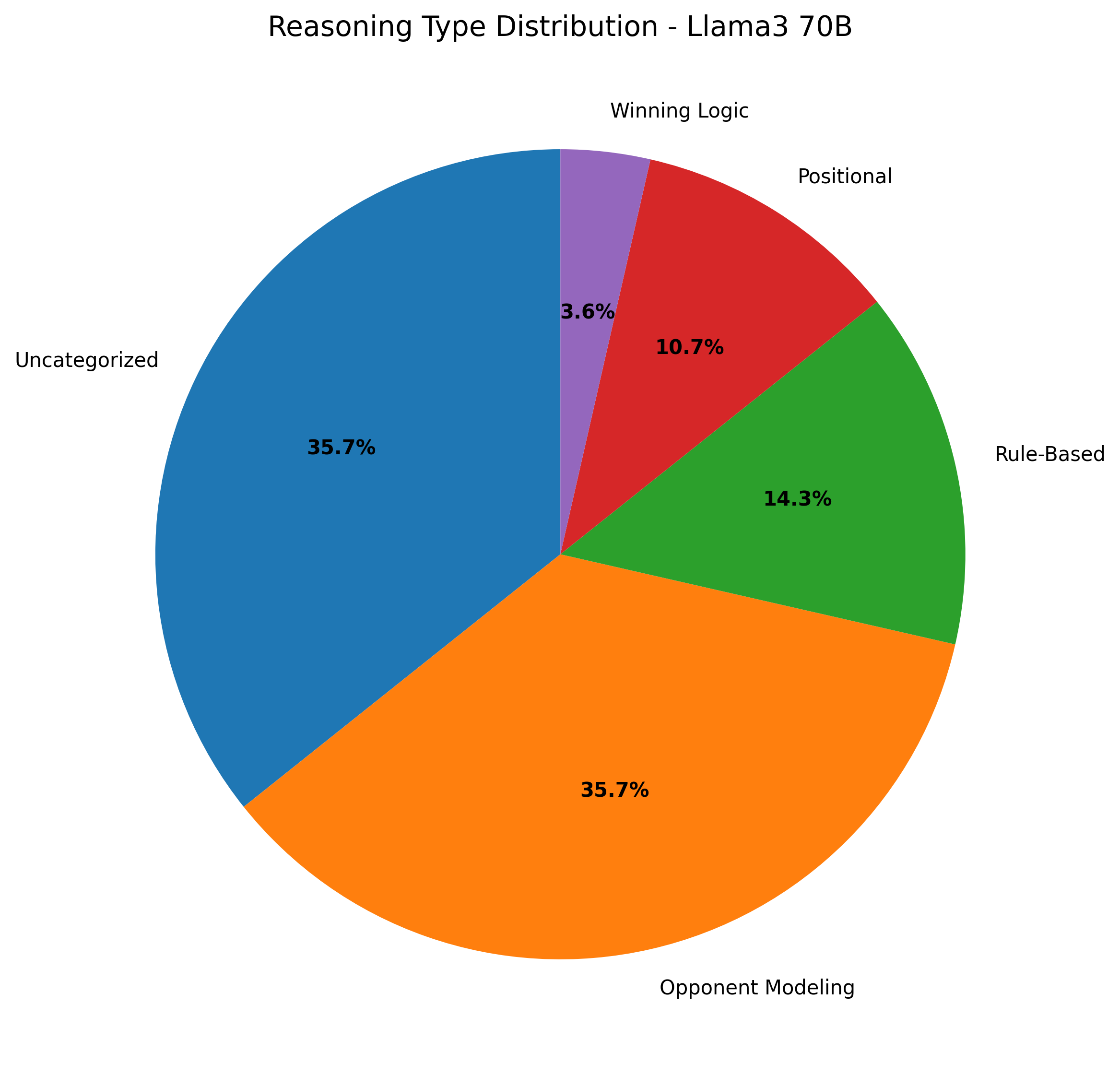
Llama3 70B demonstrates more diverse reasoning patterns with increased opponent modeling.
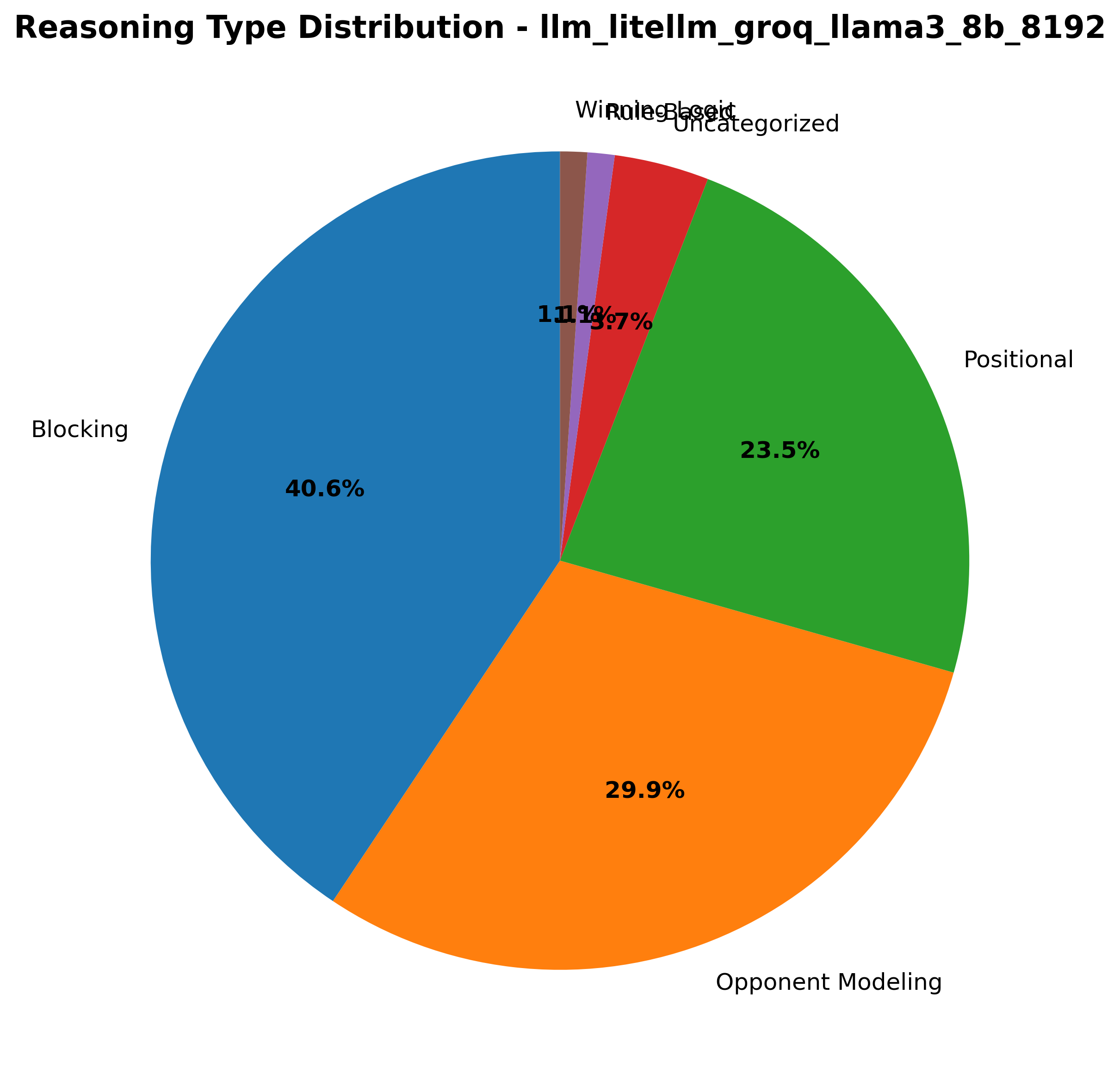
Llama3 8B shows strong preference for positional reasoning and blocking strategies.
Reasoning per game.
Reasoning type proportions for Llama3 8B across all games.
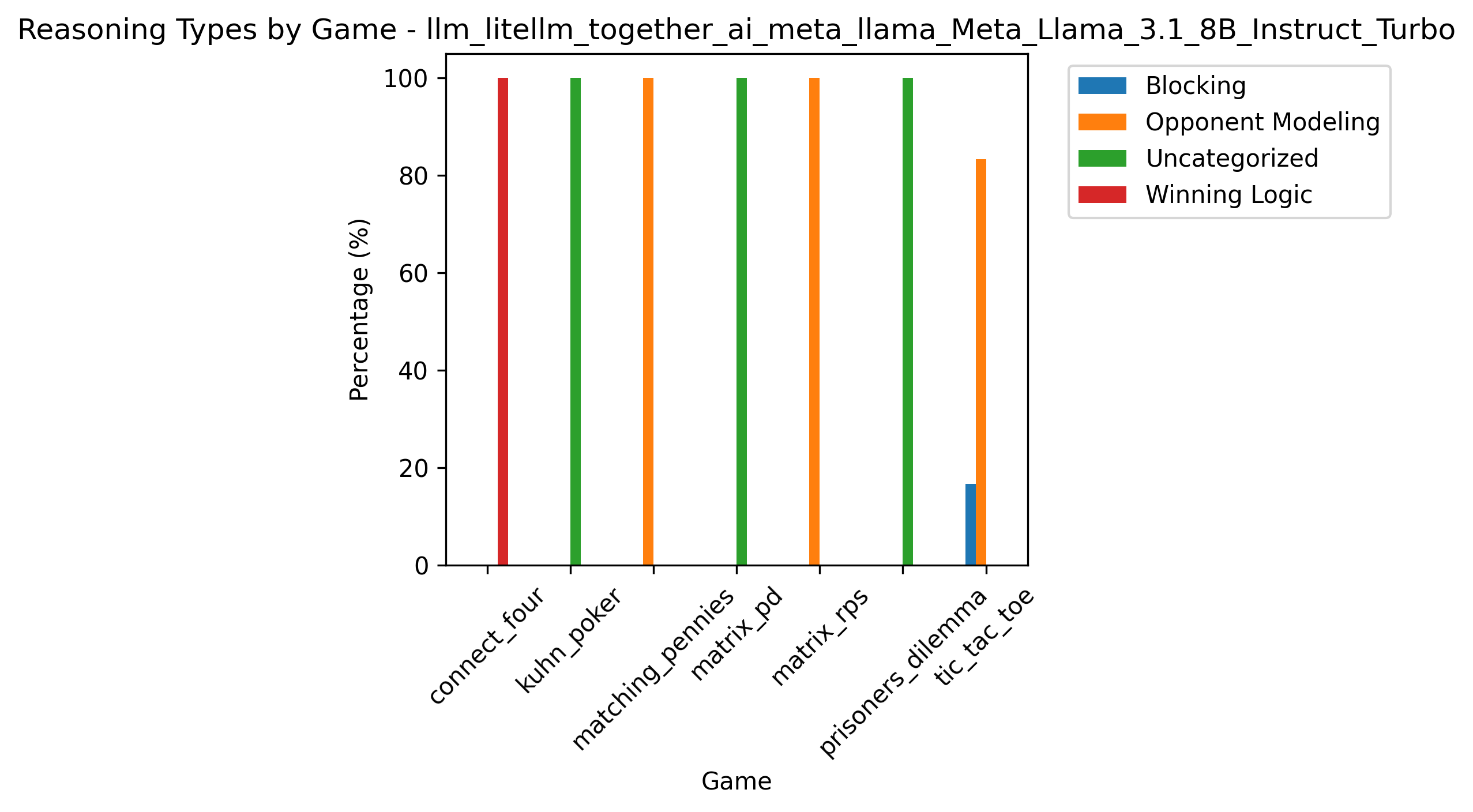
Reasoning type breakdown for Llama3.1 8B Instruct.
While Llama3 70B displays adaptive patterns across games, Llama3.1 8B Instruct often commits to a single reasoning mode for an entire match (e.g., Winning Logic in Connect Four, Opponent Modeling elsewhere).
Strategic Position Analysis
How do LLMs change their strategic reasoning as the game progresses?
Llama3 8B's positional preferences in tic-tac-toe - sophisticated spatial reasoning with balanced positional strategy.
These visualizations demonstrate how Game Reasoning Arena enables researchers to:
- Compare strategic sophistication between model sizes (8B vs 70B parameters)
- Identify reasoning pattern evolution during gameplay
- Analyze positional and tactical preferences across different games
- Quantify strategic diversity and decision-making consistency
Different LLMs not only vary in their strategic preferences but also in how flexible (or rigid) those preferences are over time. The data reveals that larger models (70B) tend to exhibit more adaptive, context-sensitive reasoning, while smaller models (8B) often commit early to a strategy and maintain it throughout the match.
Citation
@article{cipolina-kun2025game_reasoning_arena,
title={Game Reasoning Arena: A Framework and Benchmark for Assessing Reasoning Capabilites of Large Language Models via Game Play},
author={Lucia Cipolina-Kun and Marianna Nezhurina and Jenia Jitsev},
year={2025},
journal={arXiv},
url={https://arxiv.org/abs/2}
}
Community
- Issues: Bug reports and feature requests via GitHub
- Contributions: New games, agents, and analysis tools are welcome
- Research Collaboration: Contact the authors for academic partnerships
Acknowledgments
We acknowledge co-funding by EU from EuroHPC Joint Undertaking programm under grant no. 101182737 (MINERVA) and from Digital Europe Programme under grant no. 101195233 (openEuroLLM) as well as funding by the Federal Ministry of Education and Research of Germany (BMBF) under grant no. 01IS24085C (OPENHAFM), under the grant 16HPC117K (MINERVA) and under the grant no. 01IS22094B (WestAI - AI Service Center West).
This work was supported by the compute resources of Jülich Supercomputing Centre (JSC). We further gratefully acknowledge storage resources on JUST granted and operated by JSC and supported by Helmholtz Data Federation (HDF).
We also would like to express gratitude to all the people who are working on making code, models and data publicly available, advancing community based research and making research more reproducible. Specifically, we would like to thank all the members of the LAION Discord server community and Open-$\Psi$ (Open-Sci) Collective for providing fruitful ground for scientific exchange and open-source development.
We further acknowledge the contributions of the OpenSpiel developers – Marc Lanctot, John Schultz, and Michael Kaisers – whose framework provides the foundation for strategic AI evaluation.
Game Reasoning Arena is released under a CC BY-NC 4.0 license, making it freely available for research and non-commercial applications.