VIDEO2DATASET: A SIMPLE TOOL FOR LARGE VIDEO DATASET CURATION
by: Maciej Kilian, 10 Jul, 2023
Within only two years large foundational models like CLIP, Stable Diffusion, and Flamingo have fundamentally transformed multimodal deep learning. Because of such models and their impressive capabilities to either create stunning, high-resolution imagery or to solve complex downstream tasks, joint text-image modeling has emerged from a niche application to one of the (or maybe the) most relevant topics in today’s AI landscape. Remarkably, all these models, despite addressing very different tasks and being very different in design, share three fundamental properties as the main drivers behind their strong performance: A simple and stable objective function during (pre-)training, a well-investigated scalable model architecture, and - probably most importantly - a large diverse dataset.
As of 2023, multimodal deep learning is still heavily focusing on text-image modeling, while other modalities such as video (and audio) are only sparsely investigated. Since the algorithms to train the above models are usually modality agnostic, one might wonder why there aren’t strong foundational models for these additional modalities. The reason for this is – plain and simple – the lacking availability of large scale, annotated datasets. As opposed to image modeling, where there are established datasets for scaling such as LAION-5B, DataComp, and COYO-700M and scalable tools as img2dataset, this lack of clean data hinders research and development of large multimodal models especially for the video domain.
We argue that overcoming this data problem is a core interest of (open source) multimodal research since it can foster important previously impossible projects such as high quality video and audio generation, better pre-trained models for robotics, movie AD for the blind community, and more.
 Figure 1: video2dataset allows to easily create large scale collections of videos as the ones in the above sample created from available research datasets.
Figure 1: video2dataset allows to easily create large scale collections of videos as the ones in the above sample created from available research datasets.
Solution: Flexible dataset curation tooling
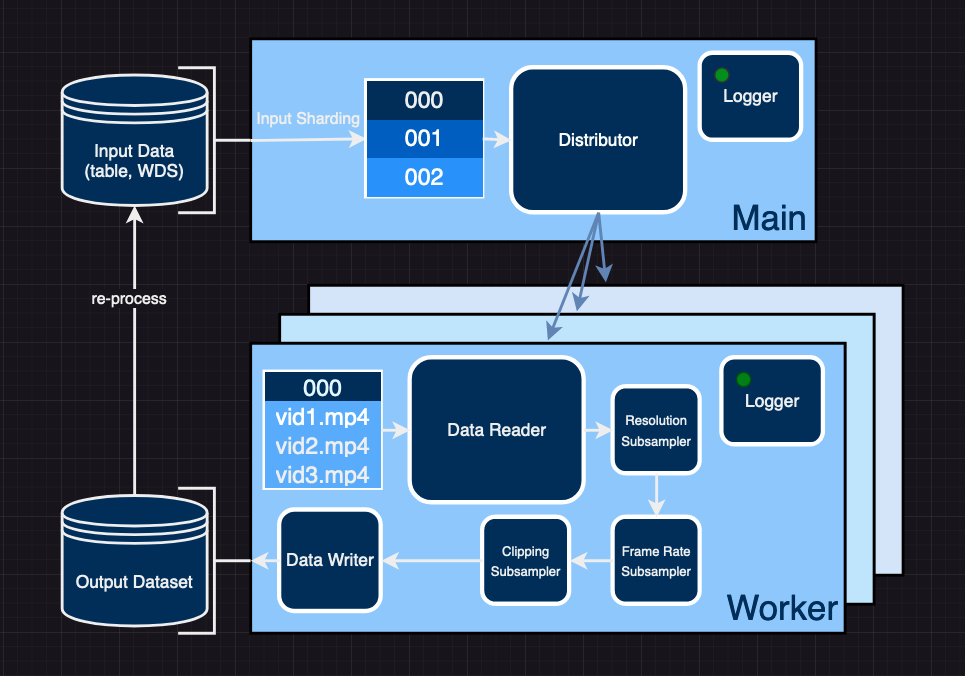 Figure 2: video2dataset architecture
Figure 2: video2dataset architecture
We introduce video2dataset, an open-source tool designed to curate video and audio datasets efficiently and at scale. It's flexible, extendable, offers a wide variety of transformations, and has been successfully tested on various large video datasets. All these examples are available in the repository, along with instructions for replicating our process.
We’ve also used video2dataset to build upon existing video datasets by downloading them individually, combining them, and transforming them into more convenient shapes with new features and considerably more samples. See the examples section for a more detailed explanation of this chain-processing. The tool’s effectiveness is showcased through the results we obtained by training various models on the datasets produced by video2dataset. An in-depth analysis of the new dataset and results will be included in our upcoming paper.
Architecture
video2dataset is built on the foundation of img2dataset and is designed to transform a table of URLs and metadata into an easily loadable WebDataset in just one command. Furthermore, it allows you to reprocess the WebDataset for additional transformations while retaining the same shard contents. Let's break down how video2dataset operates.
Input Sharding
The process begins with sharding the input data, a step that enables easy distribution among the workers. These input shards are temporarily stored, and the 1-1 correspondence between input and output shards ensures seamless resumption following any failures. If a dataset processing run stops prematurely, we can conveniently bypass processing the input shards for which the output shard already exists.
Distribution and Reading
Post-sharding, the individual shards are distributed among the workers, who read each shard and process the samples inside. For distribution we support 3 modes - multiprocessing, pyspark, and slurm - the first is good for single machine jobs whereas the last two can help with distributing across many machines. The reading method varies depending on the input dataset's format. For instance, if it's a table of links, video2dataset downloads the video from the web. video2dataset supports a wide variety of video platforms by using yt-dlp to download videos it can’t directly request. However, if it's an existing WebDataset with videos, an existing webdataset dataloader reads the bytes or frames in tensor format from those samples.
Subsampling
Once the video is read and the worker has the video bytes, they are sent through a pipeline of subsamplers defined in the job config. This step optionally transforms the video through actions such as frames per second (FPS) or resolution downsampling, clipping, scene detection, and more. Alternatively there are subsamplers that are meant to only extract metadata from the input modalities like resolution/compression information, synthetic captions, optical flow, or others and include it in the metadata of a given sample. If your desired transformation isn’t already in video2dataset, its very easy to add it by defining a new subsampler or adjusting an existing one. This can be done with minimal changes in other locations of the repository and is a very welcomed contribution.
Logging
Throughout the entire process, video2dataset meticulously logs vital information at various stages. Upon completion of each shard a corresponding {ID}_stats.json file is generated. This file contains key details, such as the number of samples processed, the number of successful operations, and a log of any failures along with their associated error messages. For added functionality, video2dataset also supports integration with Weights & Biases (wandb). This integration can be activated with a single argument and, when enabled, it provides extensive performance reporting, along with success and failure metrics. Such features are helpful for benchmarking and cost-estimating tasks related to full jobs.
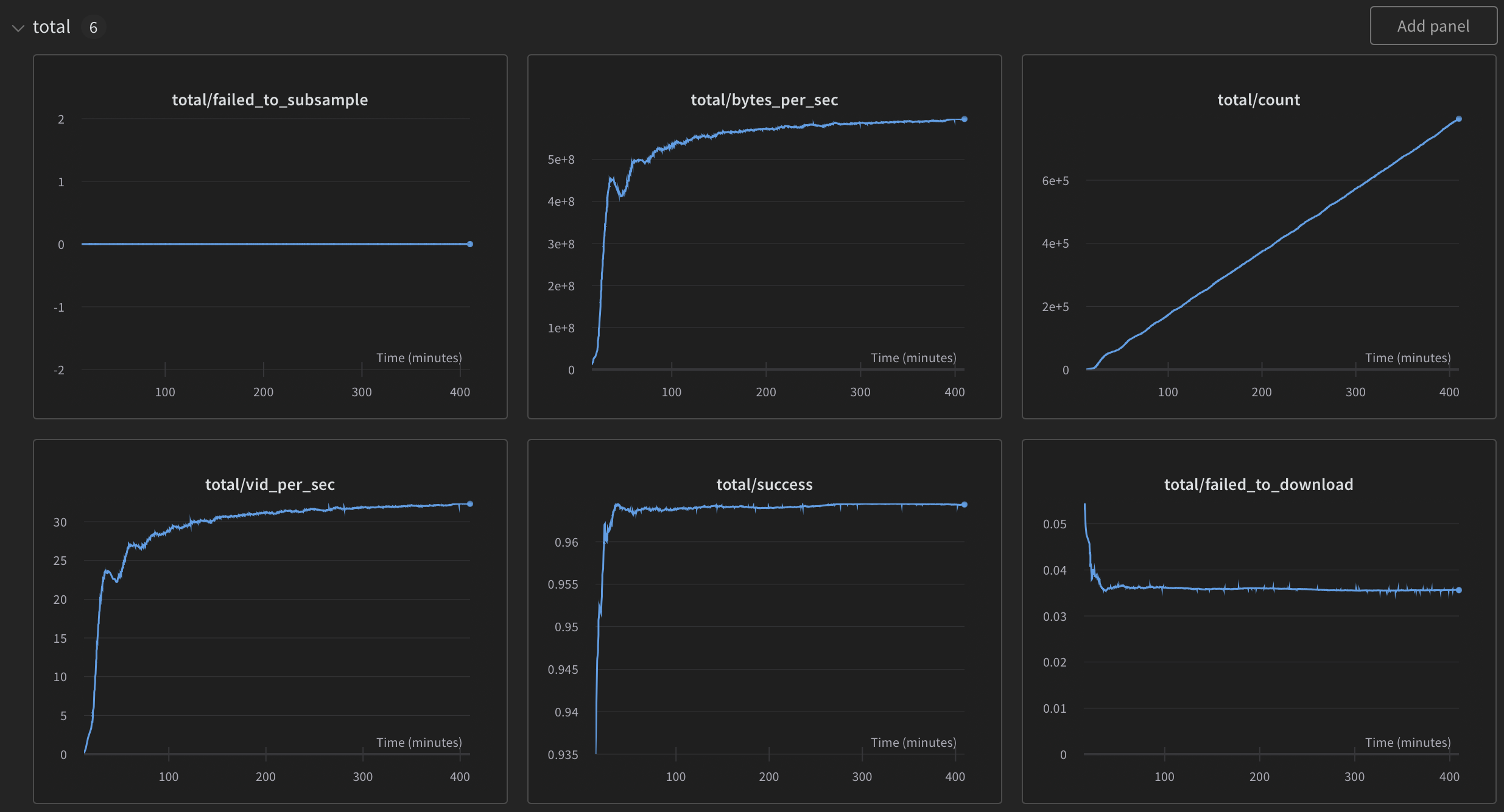 Figure 3: Part of a wandb report from a large video2dataset run
Figure 3: Part of a wandb report from a large video2dataset run
Writing
Finally, video2dataset saves the transformed data to output shards in specified locations, where they can be utilized for training or reprocessing with video2dataset or other tools. The output format of the dataset is shards of N samples each where the shards can be formatted in multiple ways - directories, tar files, tfrecords, or parquet files. The most useful ones are the directories format for smaller datasets and debugging and tar files which is used by the WebDataset format for loading. Here is a visualization of the output datasets:
video-dataset
├── 00000.tar
| ├── 00000.mp4
| ├── 00000.txt
| ├── 00000.json
| ├── 00001.mp4
| ├── 00001.txt
| ├── 00001.json
| └── ...
| ├── 10000.mp4
| ├── 10000.txt
| ├── 10000.json
├── 00001.tar
| ├── 10001.mp4
| ├── 10001.txt
| ├── 10001.json
│ ...
...
Reprocessing
video2dataset can reprocess previous output datasets by reading the output shards and passing the samples inside through new transformations. This capability is particularly beneficial for video datasets, given their often hefty size and unwieldy nature. It allows us to conservatively downsample our data to avoid multiple downloads of large datasets. We delve into a practical example of this in the next section.
Examples
Tree of Datasets
Each video is a rich source of data that can be decomposed into many forms - different resolutions, the audio, the motion (optical flow), individual frames - and dataset tooling should reflect this flexibility. One initial download of raw videos can be efficiently expanded into a variety of datasets for many different projects. For example, a research group might use video2dataset and its chain-processing capabilities in the following way to accommodate many research projects with diverse data:
Figure 4: You can efficiently extract many types of datasets from an initial base set of video links using video2dataset
The individual steps are:
- Download an HD video dataset for a generative video modeling project.
- Download 2 more datasets at various resolutions so you can increase your sample count
- Combine all 3 video datasets and downsample in resolution and FPS so it can be more easily stored.
- Train a contrastive video-text model on the downscaled, diverse dataset
- Extract audio and useful metadata out of the downscaled dataset.
- The audio can be used to train various audio models (generative or discriminative)
- The metadata can be used to filter the dataset. For example one could use the optical flow to filter out low-motion videos.
- We can further process the audio and extract transcripts (using our WhisperX subsampler)
- The transcripts can be used to train text-only or vision-text models
Doing dataset curation using video2dataset is very convenient across projects since datasets with the same contents can share metadata shards - the audio dataset from step 6 can use the same captions as the contrastive video-text model in step 4; we may filter that audio dataset with the same optical flow scores produced in step 5.
Dataset processing jobs
We have used video2dataset to process many popular datasets and we include instructions for how to reproduce these jobs in the dataset_examples section of the repository. One such dataset is WebVid (10M samples) which can be downloaded in 12h on a single cpu16 EC2 instance which costs 8.16$ in total. To further test video2dataset’s capabilities, we create a large scale video-text dataset (590M pairs) by combining existing large datasets and performing extensive processing on them using video2dataset transformations. Specifically, we perform scene detection, clip according to those scenes, add synthetic captions and add optical flow estimates for each clip. The dataset will be released soon along with a discovery study on its applicability
Metadata and Statistics
video2dataset can be used to gather various metadata and statistics about the processed data. Some subsamplers have the goal of taking a given modality (video, audio) and extracting metadata from it like compression/video information, optical flow scores, audio transcripts etc. Additionally during downloading if the source already has associated metadata, like f.e. Youtube videos do, video2dataset will try to extract that metadata and place it in the webdataset so you can later access it easily. Here are some examples:
| Video | Optical Flow | Synthetic Caption | Whisper Transcript | YouTube Metadata |
|---|---|---|---|---|
 |
 |
crowd of people at a music festival | {"segments": [{"text": " Okay, hold tight everybody in the back. Hold tight everybody in the middle. Hold tight everybody", "start": 0.008, "end": 5.257}], "language": "en"} | {..., "title": "NassFestival [Bugzy Malone]", "categories": ["People & Blogs"], "tags": ["bugzy malone", ...], "view_count": 3081, "like_count": 7, ...} |
 |
 |
the video shows you how to solve a multiplication problem | {"segments": [{"text": " 1 2 1 6 7 is 3 for finding the remaining digit of the answer we need to divide the number into two parts that is in this problem the number is 1 2 1 6 7 so first part is 1 6 7 and second", "start": 0.008, "end": 19.955}], "language": "en"} | {..., "title": "How to Find Cube Root of Any Number without calculator How To Calculate Cube Roots In Your Head math", "categories": ["Education"], "tags": ["find cube root of a number", ...], "view_count": 399080, "like_count": 5498, ...} |
 |
 |
a drone is flying over a field | No Speech | {..., "title": "Nike Smoke", "categories": [], "tags": [], "view_count": 8164, "like_count": 64, ...} |
YouTube provides a large amount of metadata for each video so we only select a few keys for display here. For a full example of a youtube metadata dictionary see this example.
What’s next?
- Scientific analysis and release of a large scale dataset created with the tool presented in this blog post.
- Improved synthetic captioning. Synthetic captioning for videos is still underexplored and there’s many exciting ideas to try. Soon in video2dataset we will have more interesting methods to produce captions for videos that make use of image captioning models and LLMs.
- Since its release people have been talking about using Whisper to obtain many text tokens from video. This is possible with video2dataset and we are working on transcribing a large corpus of podcasts which we will soon release as a text dataset (we are aiming at 50B tokens).
- Many exciting modeling ideas. Hopefully with the improvement of dataset curation tooling more people will attempt to push the SOTA in the video and audio modality.
Contributing
video2dataset is a fully open-source project and we are committed to developing it in the open. This means all the relevant TODO’s and future directions can be found in the issues tab of the repository. Contributions are welcomed and the best way of doing that is to pick out an issue, address it, and submit a pull request.
License
MIT
Contributions
Big thanks to everyone involved, most notably:
- Romain for building out img2dataset, helping with the initial design of video2dataset, and giving lots of advice during the process of building video2dataset.
- Marianna for helping create the audio functionality.
- Daniel for building the cut detection and optical flow capabilities. Also for extensive help with testing and runs at scale, and feedback on the blogpost.
- Andreas for greatly improving the video2dataset dataloader and implementing slurm distribution.
- Sumith for implementing synthetic captioning and lots of help during writing the blogpost (especially with visualizations).