INTRODUCING VISIT-BENCH, A NEW BENCHMARK FOR INSTRUCTION-FOLLOWING VISION-LANGUAGE MODELS INSPIRED BY REAL-WORLD USE
by: Yonatan Bitton, 15 Aug, 2023
[Paper] [Code] [Dataset] [Leaderboard]
We are thrilled to introduce VisIT-Bench, a benchmark for evaluating instruction-following vision-language models (VLMs). The central goal of VisIT-Bench is to provide a more accurate and meaningful assessment of VLMs, particularly in the context of human-chatbot interactions inspired by real-world scenarios.
VisIT-Bench comprises 678 examples. Each example includes:
- An image (or multiple images)
- An instruction
- An "instruction-conditioned caption" - a detailed caption allowing a text-only entity to follow the instruction
- A GPT-4 response suggestion
- A label verifying the accuracy of the response

VisIT-Bench comes with an easy automatic evaluation that correlates well with human preferences from over 5,000 annotations. Our evaluations underscore a clear need for advancement in VLMs. The top model on our benchmark exceeded the human-verified GPT-4 reference in only 27% of comparisons, highlighting both the challenges and potential for future progress in this area.
Why VisIT-Bench?
Though recent VLMs have shown promise in following instructions, their evaluation for real-world human-chatbot instructions is often limited. Typically, VLMs are evaluated through qualitative comparison of outputs, which makes it challenging to quantify progress and potential shortcomings. VisIT-Bench helps address this problem by offering a comprehensive testbed for measuring model performance across a diverse set of instruction-following tasks, inspired by real world scenarios.
Building the Benchmark
To maximize the variety of skills needed for evaluation, VisIT-Bench draws from two main sources: new instruction collection and the repurposing of existing datasets. This dual-source approach ensures a comprehensive assessment of multimodal chatbots.

Data Collection Framework
VisIT-Bench is a benchmark consisting of 679 vision-language instructions. Each instruction pairs an image with a corresponding request or question. For example, an image might depict a storefront with two portable wedge ramps, accompanied by the question: Would a disabled wheelchair-bound individual find it easy to go into this store? Contrary to prevalent zero-shot evaluations, many instructions emphasize open-ended generation requests, like write a poem... or what should I bring if I were to visit here?.
VisIT-Bench employs a structured data collection strategy encompassing four steps.
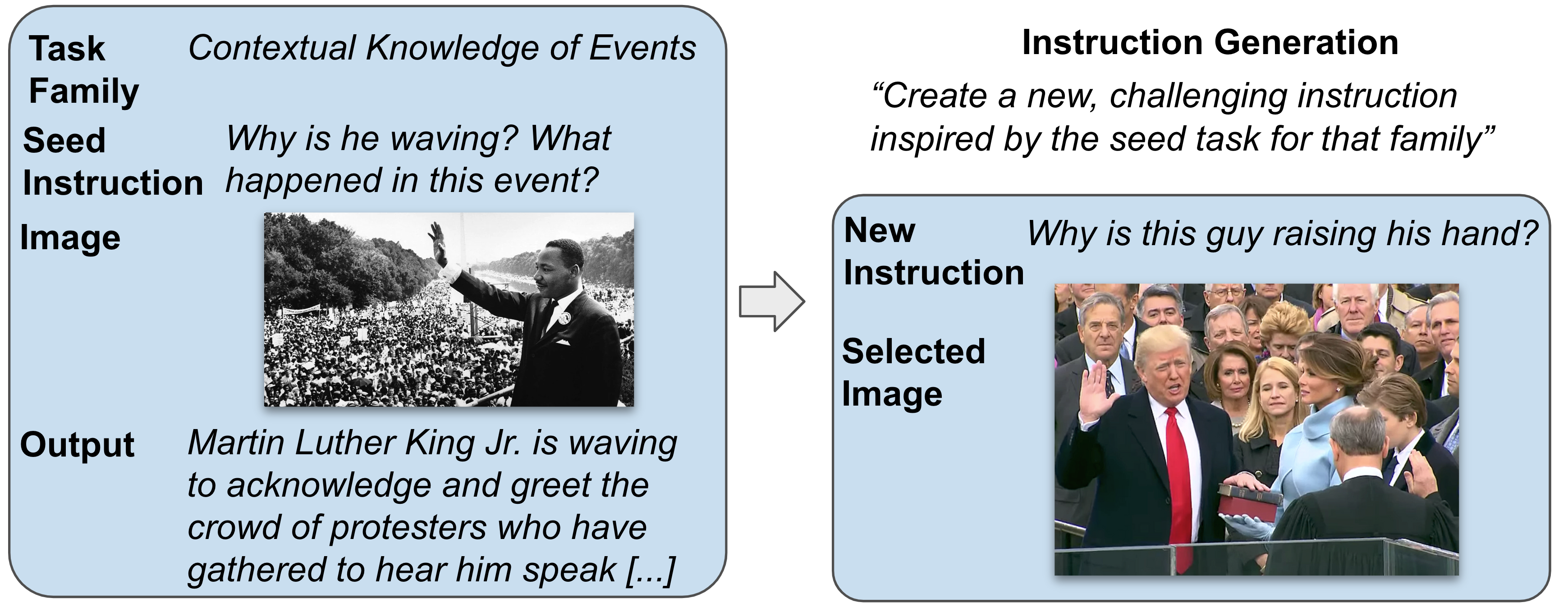
(1) Instruction Generation: Convert a single example from a skill category into multiple instances. Using references from an instruction family (instruction, image, model output), annotators craft new instructions linked to a public image URL. For instance, under the Contextual Knowledge of Events family, an instance about a related event might be generated.
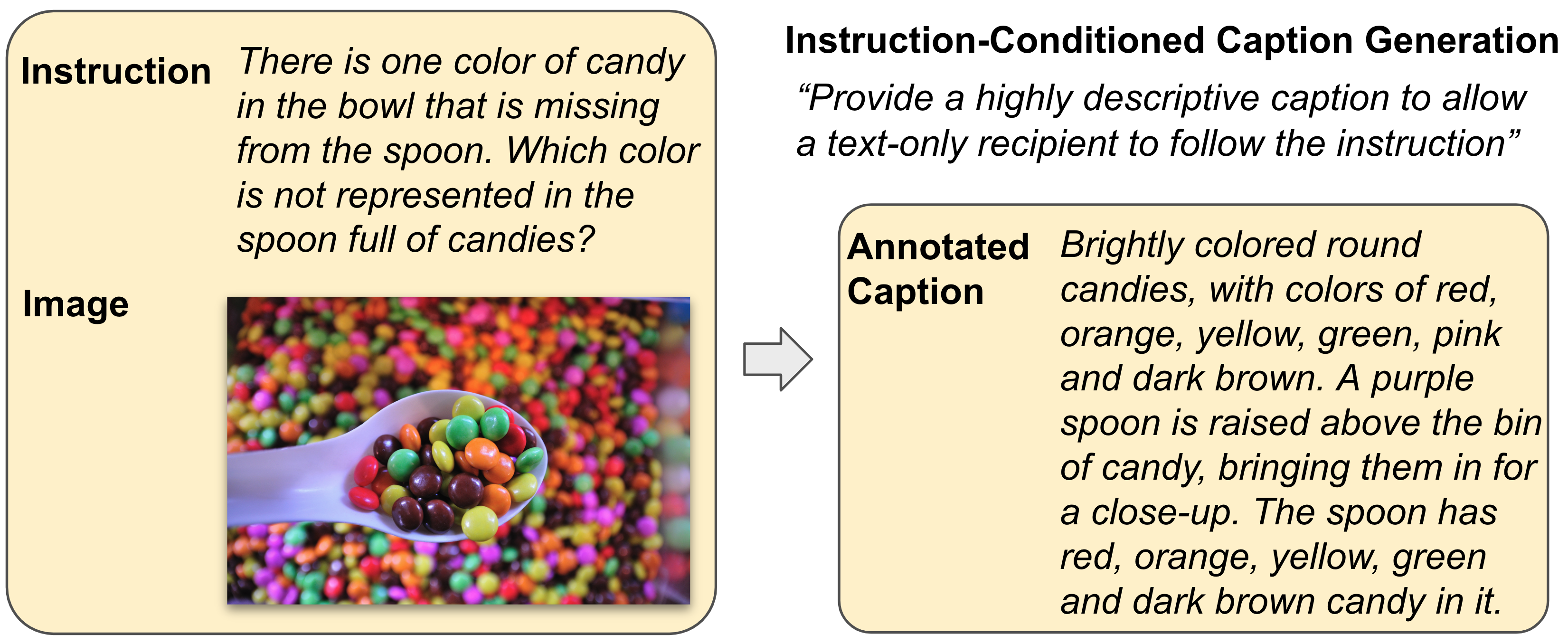
(2) Instruction-Conditioned Caption Generation: Annotators produce detailed captions for each image, based on the given instruction and image. The aim is a text-rich caption enabling text-only comprehension, which serves as a foundation for GPT-4 outputs and text-only evaluations.
(3) Generating GPT4 Responses: Response candidates from GPT-4 are fetched for later human validation. Using the prompt: “Consider an image depicted by: <caption>. Follow this instruction: <instruction>. Response: “.
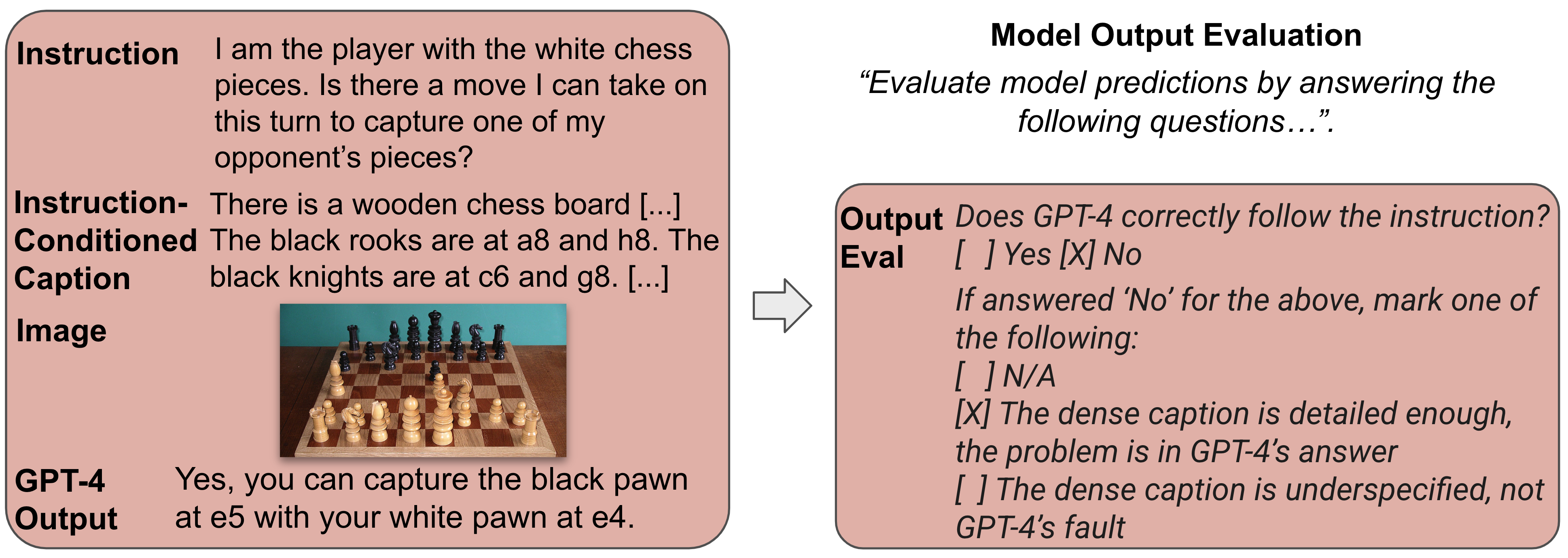
(4) Model Output Evaluation: GPT-4's instruction-following ability is assessed using text-only pairs. With the image, dense caption, instruction, and GPT-4's prediction, annotators evaluate GPT-4's adherence to instructions, pinpointing errors in captions or responses and flagging inappropriate content.
Repurposing Existing Datasets
VisIT-Bench converts 25 datasets (250 instances) into chatbot-friendly formats, including ten multi-image datasets. These datasets include VQA, VCR, TextCaps, WHOOPS! and more. Each instance consists of an instruction prompt and a chatbot response. For instance, our adaptation of the NLVR2 dataset is designed to test visual reasoning capabilities for chatbots. Originally, the NLVR2 format featured a sentence for analysis, two images, and a binary response. In our version, we incorporated a zero-shot prompt, detailed image captions aligned with the instruction, and a GPT-4-verified human response. This method is devised to enhance previous studies to align with contemporary chatbot evaluation metrics.

Features of the Dataset
VisIT-Bench is a unique composition of 70 unique instruction families, 25 repurposed prior datasets, including 10 multi-image datasets, each embodying a different skill that a chatbot model should ideally exhibit. These families mirror practical real-world chatbot interactions, thus ensuring that our benchmark evaluates models against realistic and varied tasks.
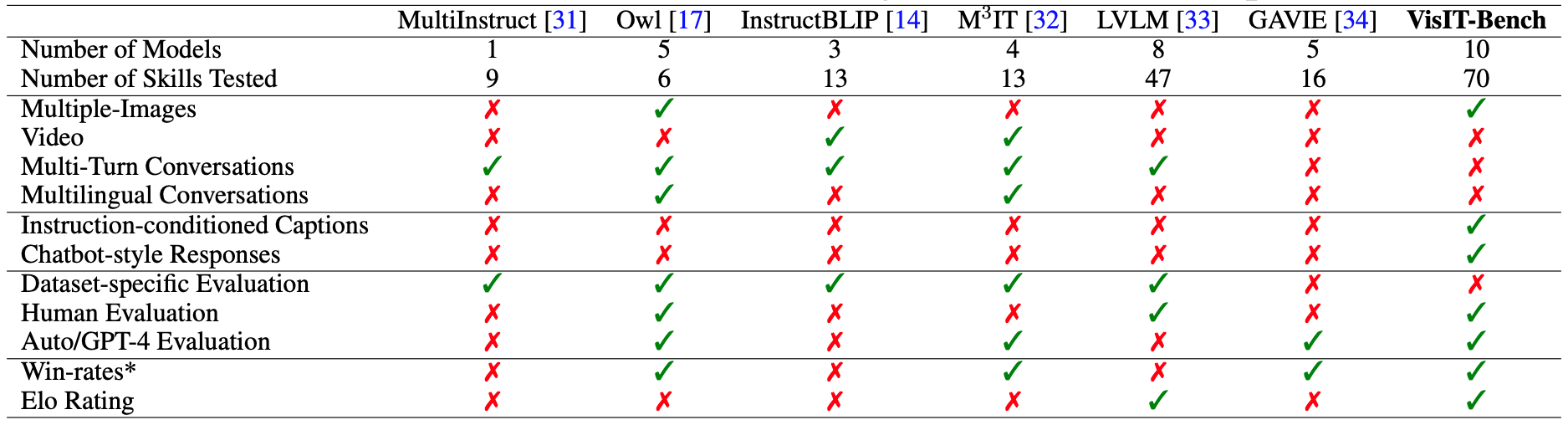
Models
Our evaluation includes a variety of publicly accessible vision-language models, either fine-tuned with multimodal instructions or designed to execute based on LLM outputs. These models include LLaVA-13B, InstructBLIP-13B, MiniGPT4-7B, mPLUG-Owl-7B, LlamaAdapter-v2-7B, PandaGPT-13B, VisualChatGPT, Multimodal GPT, OpenFlamingo v1, and Otter v1.
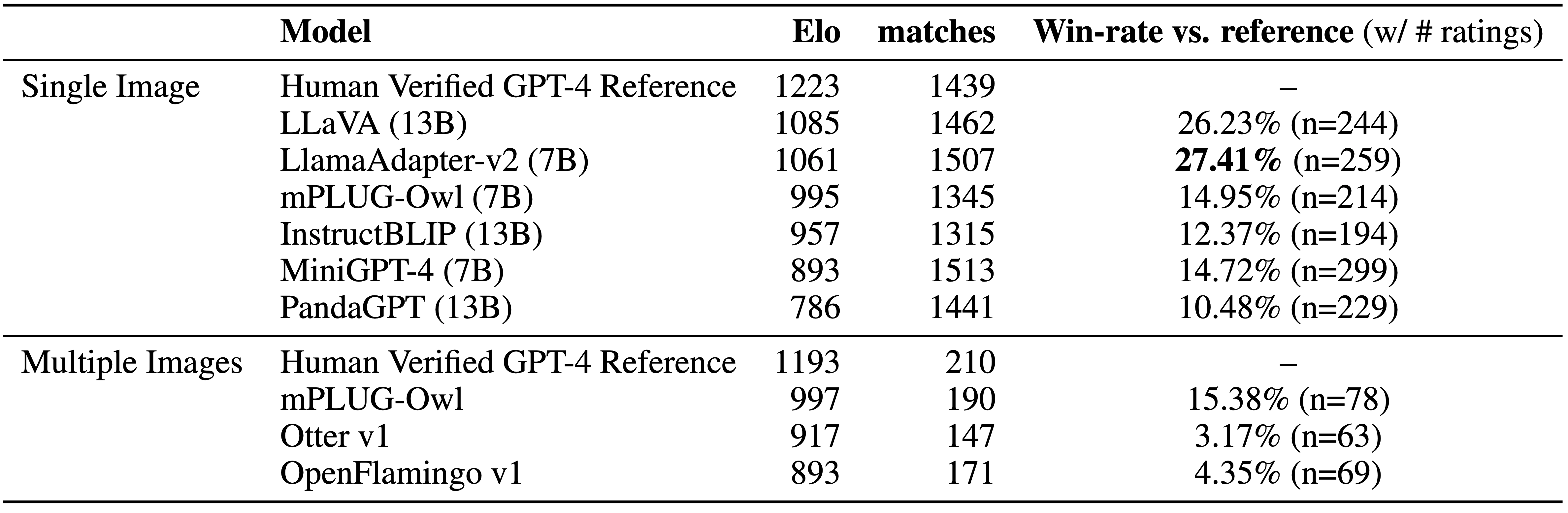
Human-Guided Rankings
Using VisIT-Bench's single-image examples, we created 5,000 pairwise comparisons across multiple vision-language models. Each model was in about 700 comparisons, including GPT-4's outputs. Three annotators blind to the model origins ranked the outputs for correctness and comprehensiveness. Results underscore the effectiveness of GPT-4 and LLaVA (13B) on this dataset. GPT-4's success stemmed from conditioned dense captions, while LLaVA benefited from its instruction-tuning dataset. Interestingly, LlamaAdapter-v2 (7B) outperformed in direct comparisons to reference outputs, emphasizing the importance of language instruction fine-tuning for these models. The relationship between model design, task variety, and performance needs more exploration.
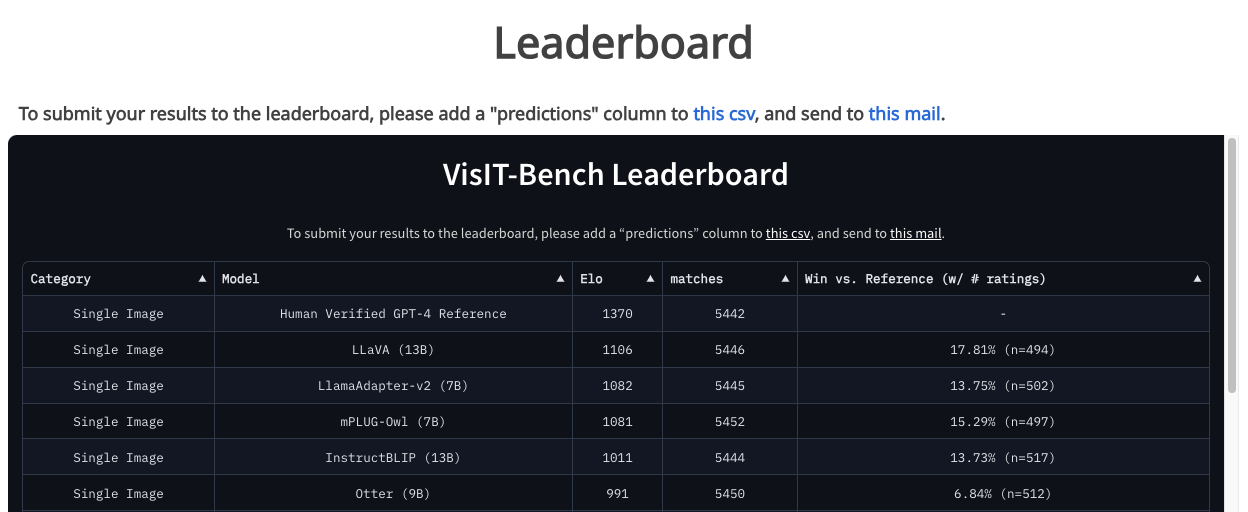
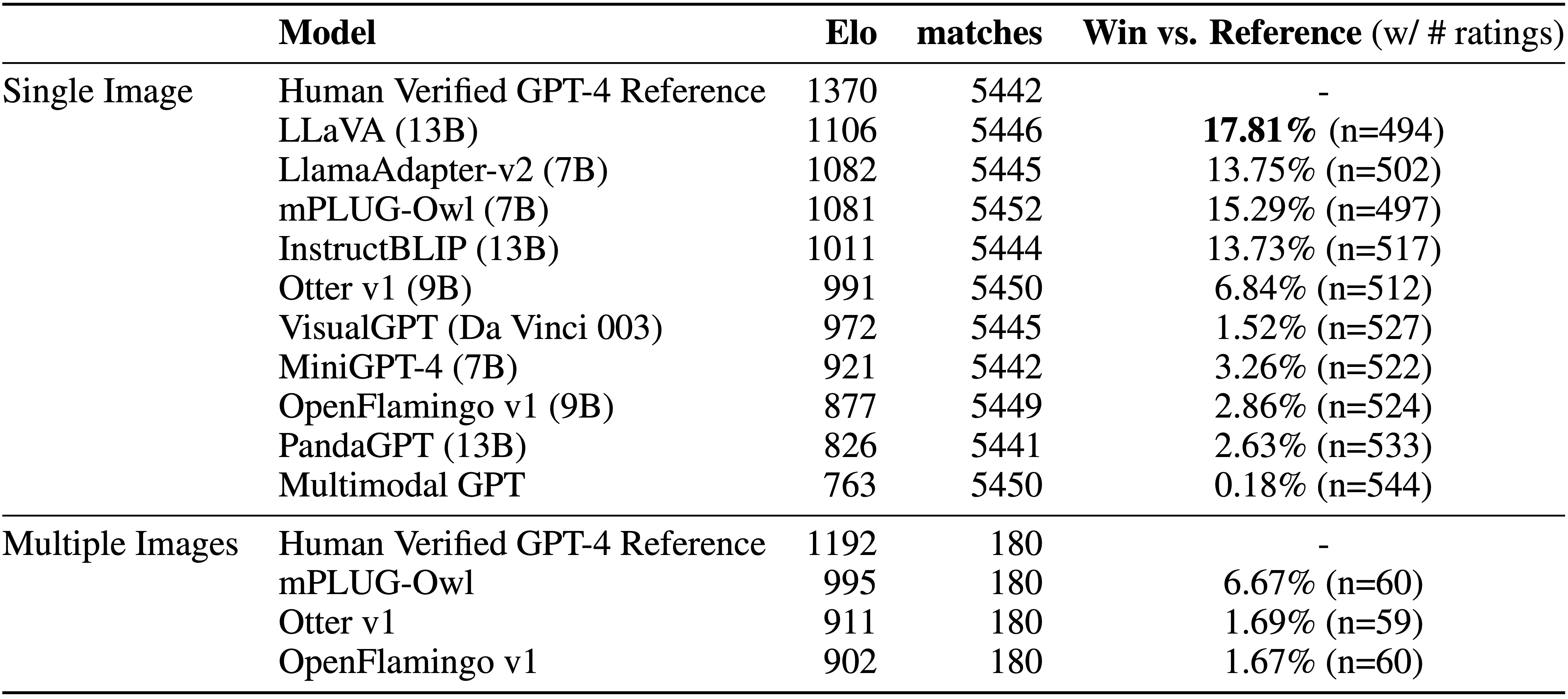
Automatic Evaluation and Dynamic Leaderboard
We introduced an automatic evaluation framework to rank model outputs, employing Elo-ratings and win-rate against the ground truth. This approach addresses potential bias, considering GPT-4 was used to assess its own output, and shows high agreement with human ratings. Metrics include: Reference-free Elo score, mirroring human evaluation; Reference-backed Elo score, incorporating the prompt's optional reference; and Win-rate against reference, indicating how often a model's output is preferred over reference. Our findings reveal consistent rankings between reference-free and backed evaluations. However, existing instruction-following models' win rates vary widely, underscoring a clear gap in their performance against reference outputs.

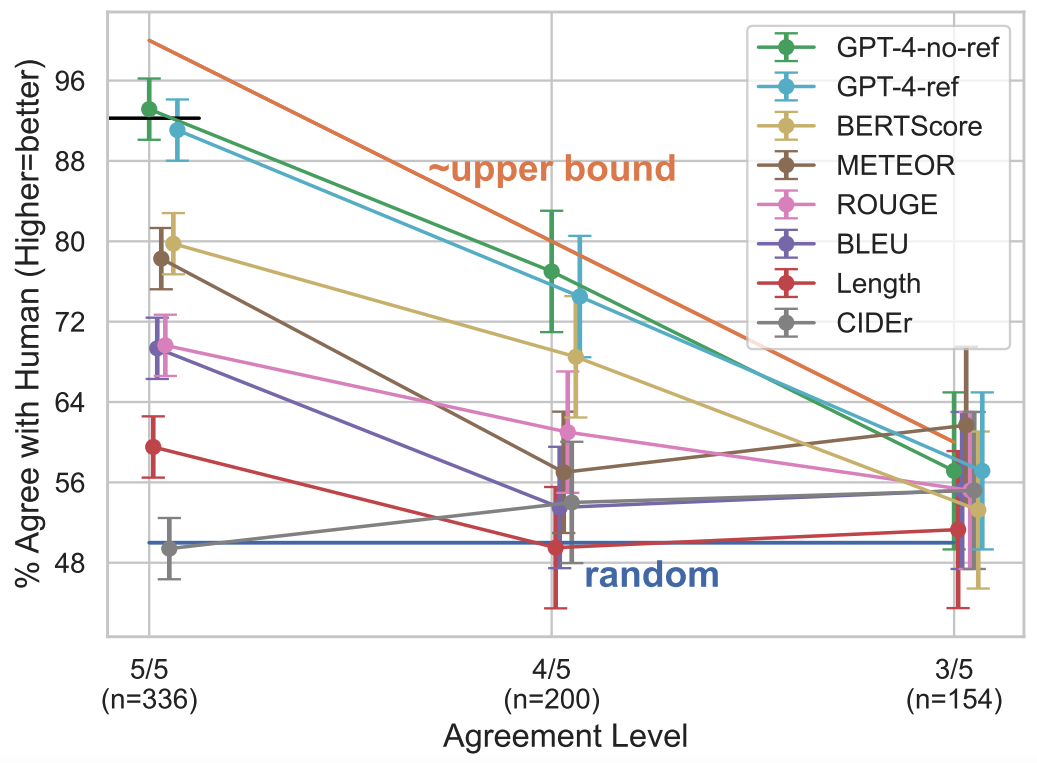
Correlation of the Automatic and Human-Annotated Preferences
Our GPT-4 based metric surpasses others, closely mirroring majority-vote human judgments. In cases with unanimous agreement (5/5 annotators), GPT4-no-ref hits 93% accuracy, outdoing BERTScore (80%), METEOR (78%), and ROUGE-L (70%). Against a length baseline metric (60%), these metrics provide viable offline evaluation options without needing OpenAI API access. The reference-free GPT-4 metric performs similarly to its reference-backed counterpart, allowing references in the evaluation setup..
Contributions
This effort was made possible thanks to the amazing team of:
- Yonatan Bitton*, The Hebrew University of Jerusalem, Google Research
- Hritik Bansal*, University of California, Los Angeles
- Jack Hessel*, Allen Institute for AI
- Rulin Shao, University of Washington
- Wanrong Zhu, University of California, Santa Barbara
- Anas Awadalla, University of Washington
- Josh Gardner, University of Washington
- Rohan Taori, Stanford
- Ludwig Schmidt, Allen Institute for AI, University of Washington, LAION
*Equal contribution.
In Conclusion
VisIT-Bench offers a comprehensive lens on VLMs by utilizing 70 carefully curated instruction families, mirroring a wide range of real-world scenarios. This approach allows an in-depth assessment of model understanding but paves the way for enhancing VLMs' performance across various tasks. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at the project website.