CALL TO BUILD OPEN MULTI-MODAL MODELS FOR PERSONAL ASSISTANTS
by: Christoph Schuhmann, 29 May, 2024
Technologies like the recently introduced GPT-4-OMNI from OpenAI show again the potential which strong multi-modal models might have to positively transform many aspects of our lives. A particularly impressive example of this is in the field of education. Imagine every person in the world having their own personal learning assistant that acts like a attentive, caring, patient, and empathetic tutor. The demo from OpenAI last Monday showed that such a vision of the future is not too far off and is within reach.
The Path to Open Multi-Modal Models
An important milestone on this path could be training an open-source model with capabilities similar to GPT-4-OMNI. The first step would be to fine-tune an existing large language model so that it can natively understand and process audio in the same way large language models currently handle text. Simultaneously, this model should be able to generate audio natively, just as it can currently output and manipulate text.
This approach had been shown to work in the AudioPalm paper:
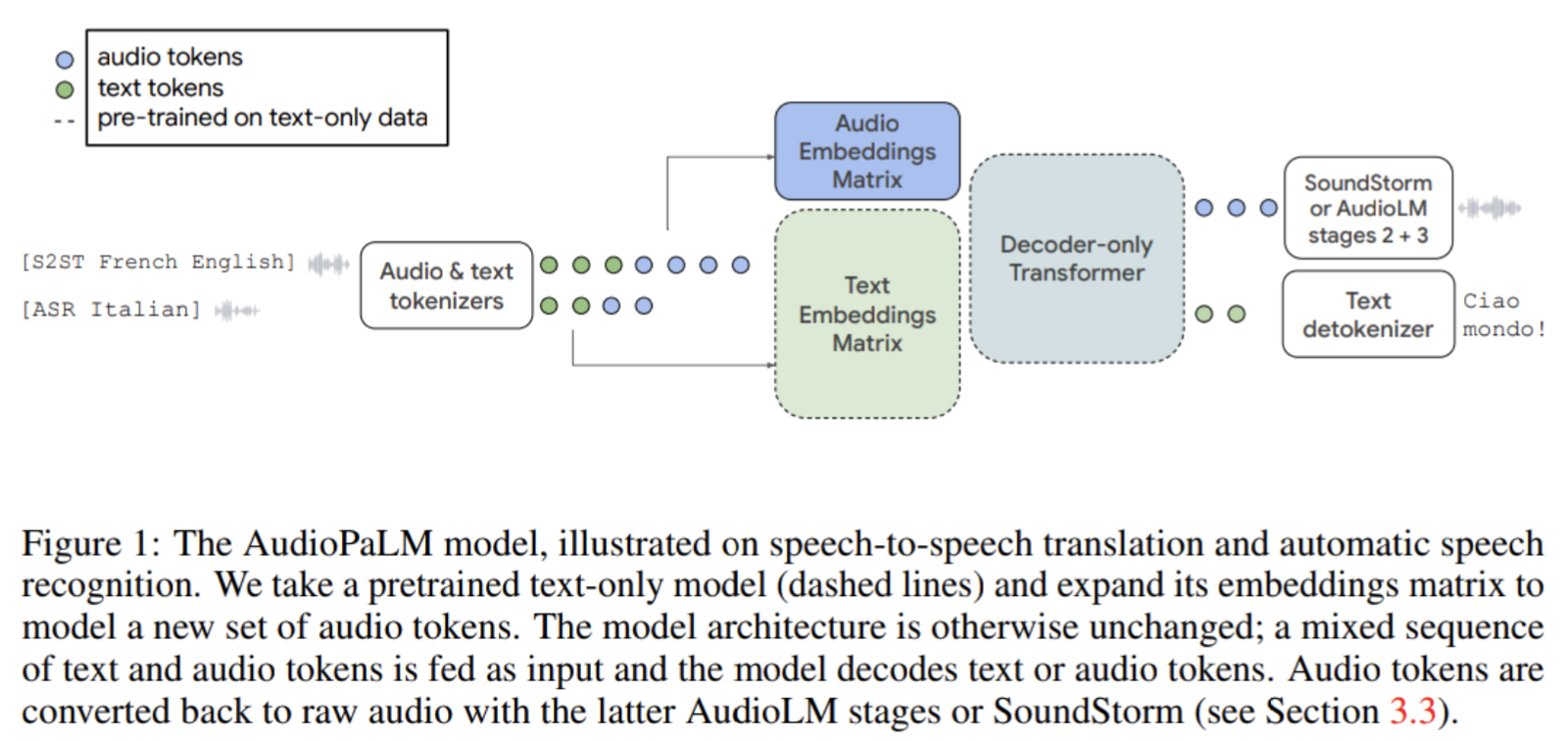
A promising approach to achieving this is converting audio signals into discrete tokens using codecs like SNAC. SNAC allows audio signals to be converted into about 80 tokens per second, enabling the language to be reconstructed in very high quality. For music, sound effects, and other general-purpose audio, other versions of SNAC demand around 200 tokens per second, enabling detailed understanding and generation of these domains. As a proof of concept, the initial goal would be to tune a large language model to process both text and audio tokens, with the 24kHz version of SNAC optimized for speech being a good starting point.
SNAC (Multi-Scale Neural Audio Codec) compresses audio into discrete codes at a low bitrate, setting itself apart from other codecs like SoundStream, EnCodec, and DAC through its hierarchical token structure. This structure samples coarse tokens less frequently, covering a broader time span, which saves on bitrate and is particularly useful for language modeling approaches to audio generation.
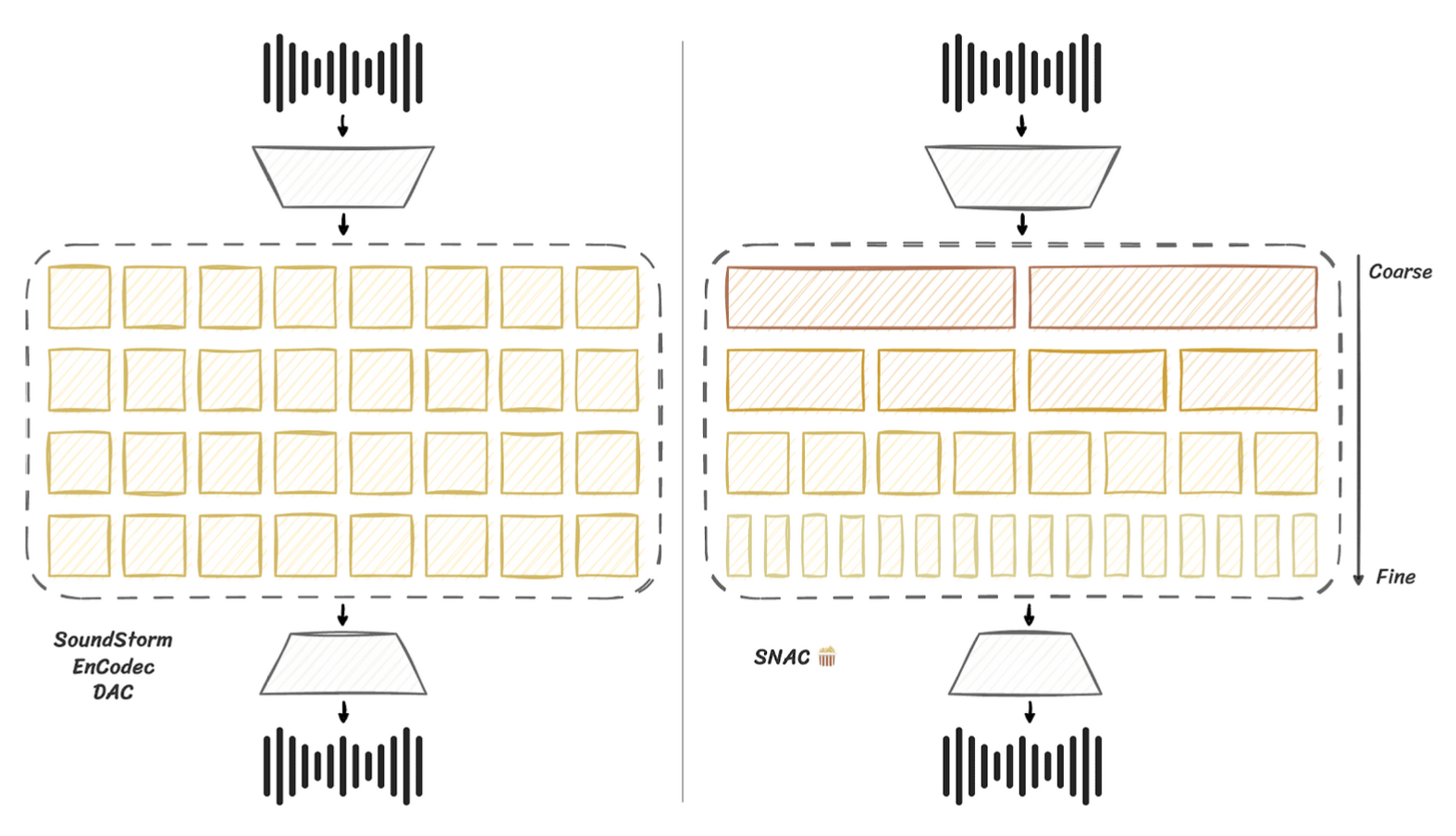
For instance, with coarse tokens of ~10 Hz and a context window of 2048, SNAC can effectively model the consistent structure of an audio track for up to three minutes. SNAC offers different types of codecs optimized for specific use cases: the 24 kHz version is tailored for speech, while the 32 kHz and 44 kHz versions are designed for general-purpose audio, including music and sound effects. This versatility and efficiency make SNAC an advantageous choice for integrating audio processing capabilities into large language models.
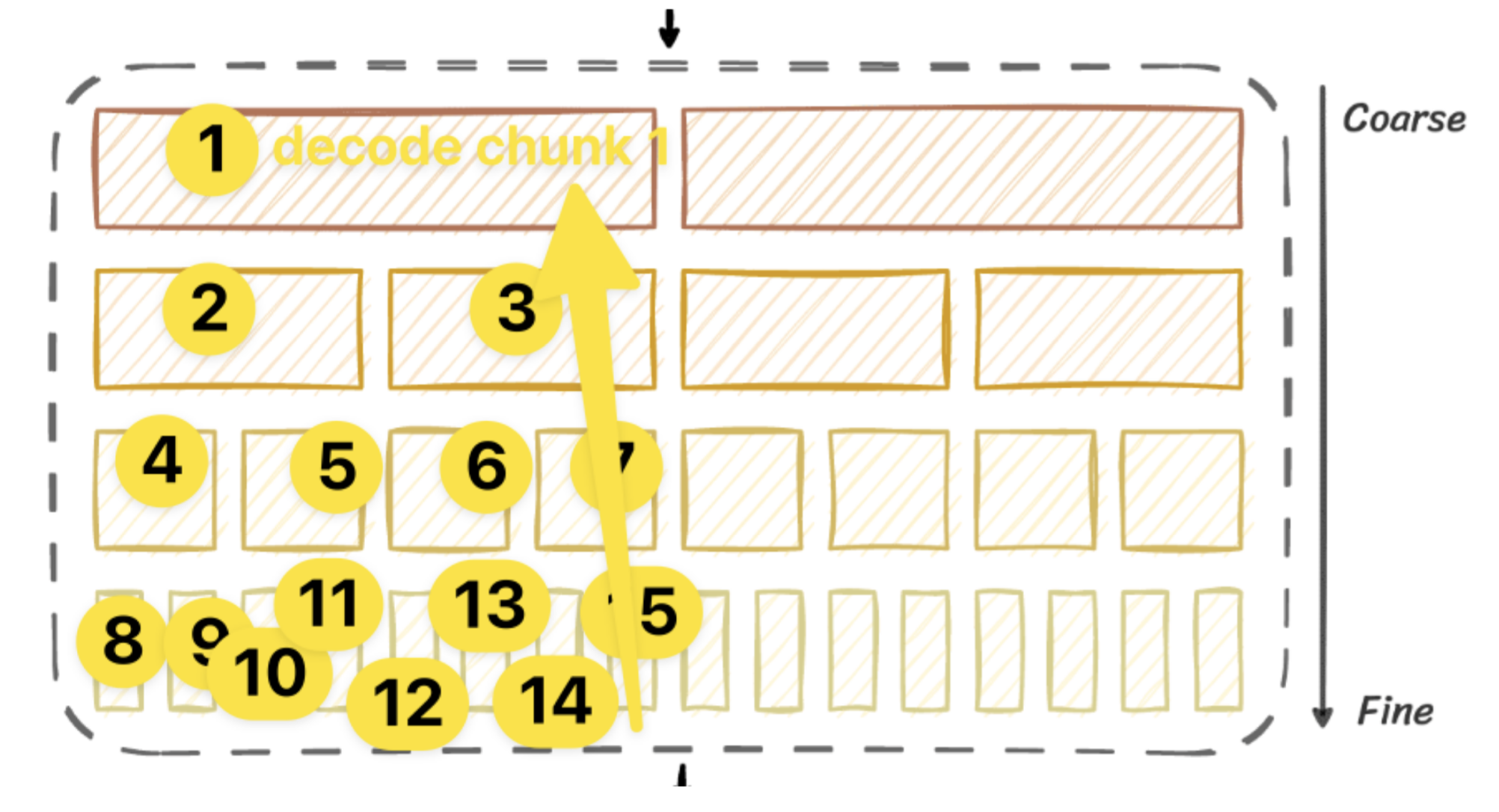
Additionally, SNAC can flatten its hierarchical structure segment-wise for each coarse token, allowing segments of approximately ~100 ms to be decoded individually and later reassembled. This depth-first flattening method facilitates low-latency streaming, making it possible to stream high-quality audio in near real-time ( Tutorial ).
Notebooks about how to use SNAC:
| SNAC Tokenization |
|---|
| 24kHz Speech Version |
| 32kHz General Purpose Version |
To advance research in this area, we have converted the parler-tts/mls-eng-10k-tags_tagged_10k_generated dataset into 24kHz SNAC tokens.
SNAC Tokenized Dataset
We call upon the community to experiment with pretraining large language models using these tokens. The first step would be to get an existing open-weights model like Llama, Mistral, Dbrx, Qwen, StableLM 2 or Phi-3 to generate SNAC tokens from text transcriptions and descriptions, functioning like a text-to-speech model. Once this works well, the next step would be training the model to see various text data simultaneously, retaining its text generation and understanding capabilities while acquiring the ability to generate audio tokens in response to questions or instructions.
This way, the model could be asked a question in text and provide an answer in SNAC tokens, which could then be directly decoded into spoken language. It would also be interesting to see how well even a small scale LLM, such as Phi-3 or Qwen-1.8B, could transcribe speech by feeding it SNAC tokens and generating a transcription text. The next step would be to train a chat model that understands SNAC tokens as input and responds with text, or directly responds with SNAC tokens to text inputs.
Once we can reliably perform functions like transcribing audio segments and generating speech in response to user queries or text inputs while maintaining the LLMs' ability to generate and understand text, we can consider extended pretraining. This involves training language models on a mixture of high-quality texts and SNAC tokens from complete, longer audio recordings. There are many publicly available sources of high-quality audio data that could impart more nuances and linguistic subtleties to the LLM than currently possible with existing ASR and TTS datasets. After extended pretraining with both text and audio data, we need instruction fine-tuning with audio-to-audio instruction datasets, where both the instruction and fulfillment are provided in audio tokens.
Audio-to-Audio Instruction Tuning Datasets
As potential sources for extended pre training of LLMs, we collected video links from sources like common crawl.
High quality podcasts, lectures & shows (330657)
For initial tests, it would be beneficial to generate both the instruction and its execution through the chatbot using TTS systems. First, we create a conventional instruction tuning dataset with a text-based LLM and then generate audio files for both the user's and the chatbot's roles with different voices. These are then converted into SNAC tokens or other audio tokens.
If this type of instruction tuning proves successful, a theoretically feasible but limited approach could be to generate an instruction tuning dataset with volunteers where one person acts as the user and another as the chatbot.
Another possibility is to perform transcription with speaker separation on podcasts, and then use an LLM like LLAMA to identify transitions where speaker 1 appears to issue a request and speaker 2 helpfully responds. These parts from speaker 1 and speaker 2 could be components in an audio-to-audio instruction tuning dataset.
Additional ideas for audio text tuning datasets are:
- Integrated Audio-Text Datasets: Create datasets where text segments are partially replaced with speech segments generated using Text-to-Speech (TTS) systems. This method helps the model learn to handle interleaved audio and text seamlessly.
- Cross-Modal Translation Tasks: Use models like Meta's SeamlessM4T to generate speech translations from one language to another. For instance, translate English audio clips to German, creating paired datasets to enhance the model’s multilingual audio capabilities.
- Music and Sound Effects Generation: Develop datasets containing music and sound effects with corresponding textual descriptions or generation instructions. This trains the model to understand and generate diverse audio outputs based on text or audio inputs.
Conclusion
As a community of volunteers and hobbyists, we cannot conduct all these experiments simultaneously. Therefore, we officially call on the open-source community to start experimenting with the datasets we have converted and share their results with us. Once we achieve promising small-scale results and eventually derive scaling laws based on the small scale experiments predicting behavior on larger scales, we can discuss how to provide computing resources for larger-scale experiments.
We look forward to your feedback and experiments. Together, we can create a future where advanced language models are accessible to all and have a positive impact on many lives.