ROOK: REASONING OVER ORGANIZED KNOWLEDGE
by: Jonathan Rahn, Jenia Jitsev & Qi Sun, 20 Jan, 2025
The field of artificial intelligence has long used strategic reasoning tasks as benchmarks for measuring and advancing AI capabilities. Chess, with its intricate rules and vast decision space, stands out as a particularly challenging domain. The game's complexity stems from its branching factor—the number of possible moves at each turn — which averages around 35, creating a search space that quickly becomes intractable for brute-force approaches.
Today, we're excited to introduce ROOK (Reasoning Over Organized Knowledge), a suite of innovative language models that push the boundaries of strategic reasoning in chess. Our approach diverges from traditional chess engines that rely heavily on search algorithms. Instead, we explore the potential of language models to capture chess knowledge and reasoning processes in a more human-like manner.
Our project comprises three chess-playing transformer models:
- ROOK-CLF
- ROOK-LM
- RookWorld-LM
| Experts | Step #1 | Step #2 | Step #3 | |
|---|---|---|---|---|
| Policy | Stockfish 16.1 | ROOK-CLF | ROOK-LM | RookWorld-LM |
| Environment | python-chess | python-chess | python-chess |
Figure 1: Overview
In this blog post, we'll introduce each of these models, explore their capabilities, methodologies, and implications for AI research. For those interested in the technical details and implementation, we encourage you to take a look at our public GitHub repositories.
2. ROOK-CLF: Replicating State-of-the-Art Chess Policy
Our journey began with ROOK-CLF, an experiment aimed at reproducing a key result from the Google DeepMind (GDM) paper "Grandmaster-Level Chess Without Search" (Ruoss et al., 2024). This paper set a new state-of-the-art for chess policies without search, and replicating its results serves as an important validation of their findings and our own methodologies. They published parts of their training code (in JAX) and their datasets (link) as ChessBench.
We focused on a small ablation study from the paper, training a 9 million parameter model ROOK-CLF-9M based on the LLaMA architecture with a classification head. Mirroring the approach detailed in section B.5 and Figure A5 of the paper, key aspects of our implementation include:
- A tokenizer with a vocabulary of 32 characters
- A fixed context length of 78 tokens
- An output space of 1968 classes, representing all possible chess moves in Universal Chess Interface (UCI) notation
We trained on the same 40 million data samples used in the GDM paper, employing a behavior cloning setup. Our results were encouraging, with ROOK-CLF-9M showing:
- 49% accuracy in predicting correct actions from the GDM dataset after 195,000 training steps (compared to approximately 55% reported in Figure A6 of the GDM paper)
- 57% accuracy on the BIG-bench Checkmate-in-One benchmark (after converting the positions from Standard Algebraic Notation to Forsyth–Edwards Notation).
These results, while not quite matching those reported in the original paper, demonstrate the replicability of the findings and provide a solid foundation for our subsequent experiments.
3. ROOK-LM: Incorporating Chain-of-Thought Reasoning
Building on the success of ROOK-CLF, we next developed ROOK-LM, inspired by recent work on pre-training language models on Chain-of-Thought data for reasoning (Ye et al., 2024). This transition marked a shift from a pure classification approach to a more flexible language modeling paradigm, allowing us to explore the generation of reasoning traces — intermediate step-by-step thought processes that lead to a final decision.
To facilitate this, we created a novel dataset rook-40m of up to 40 million chess positions in Forsyth–Edwards Notation (FEN), a standard method for describing chess positions. Each position was extracted from chess games played on Lichess in 2022, by players with ELO over 2000 and annotated with:
- The top five candidate moves
- The evaluation score for each candidate move
- The best move
These annotations were generated using Stockfish 16.1, one of the strongest chess engines available, running on the Tsubame 4.0 Supercomputer at Tokyo Institute of Technology.
Here's an example of our data format:
| Example Data | P: | 6k1/7p/ 4P1q1 /1pb1Q2p/ 2p1b3 /2P4P/ PP4P1 /R6K w - - 9 38 | M: | e5g5 a1g1 e5b8 e5h2 e5e4 | E: | -999.97 -2.97 -1.63 -6.59 -5.95 | B: | e5b8 |
|---|---|---|---|---|---|---|---|---|
| Field Explanation | Prefix | State (FEN) + padding | Delimiter | Top 5 Moves, shuffled + padding | Delimiter | Top 5 Moves Eval + padding | Delimiter | Best Move |
| Inference | Prompt | Generated Chain-of-Thought Tokens | Action |
Figure 2: rook-40m data representation.
This rich dataset allowed us to train ROOK-LM-124M - a 124 million parameter GPT-2 model for autoregressive text generation using the karpathy/LLM.c library, which leverages the original GPT2 tokenizer. We obtain 6 billion tokens from the whole rook-40m dataset.
Compared to ROOK-CLF-9M, ROOK-LM-124M increases model scale, adds more metadata for the moves in the chess parties using external data generator (Stockfish 16.1), and changes learning loss type:
- Over 13 times more parameters (124M vs. 9M)
- A more information-rich dataset (including top 5 moves and their evaluations, see also the discussion of Predictor-targets in sections 3.4 and B.5 of Ruoss et al.)
- A shift from purely supervised classification loss based on move class labels to self-supervised next token prediction with autoregressive modeling
Due to more generic loss nature compared to narrow supervised classification, we observe ROOK-LM-124M strongly underperforming ROOK-CLF-9M on benchmarks related to best move execution:
- 22.2% action accuracy on a validation split of the rook-40m dataset
- 24.4% accuracy on the Checkmate-in-One benchmark
This drop in performance is not unexpected. While ROOK-CLF was optimized solely for best move prediction via supervised classification and can only solve this narrow task, ROOK-LM learns to predict and generate all aspects of our data, including the reasoning process behind move execution. Further, the scales of our experiments are still very small.The advantage of specialized models over generically pre-trained ones is often observed at smaller scales on which we operated in our experiments, where generic pre-training procedure, being more flexible and scalable, results usually in more powerful models also for specialized tasks when further increasing scales, and the diversity of the pretraining data (eg incorporating other board games apart from chess). Testing this is the subject of our future work.
4. RookWorld-LM: Unifying Policy and World Model
Our final model, RookWorld-LM, represents a further step towards a model capable of representing full game state and reasoning about it. Inspired by recent research on using language models as world models (Li et al., 2023, Wang et al., 2024), we recognized that a truly comprehensive chess AI system should not only decide on moves but also understand the consequences of those moves — effectively modeling the entire game environment.
We began by creating a new dataset arbiter-6m (inspired by the interface design of Gymnasium) and trained a separate GPT-2 model to act as an environment simulator (dubbed “Arbiter”). Given a chess position (state) and a move (action), this model generates:
- The resulting position (observation)
- A score-signal for reinforcement learning (reward)
- Whether the game ended and if the move was legal (termination, truncation)
| Example Data | 5R2/6R1/8/ 3P4/p7/ 1b2R2P/ 2p3P1 /6K1 b - - 0 58 | b3d5 | e1e3 a2b3 f7f2 b5b4 g5g7 b4c3 f2f8 c3c2 d4d5 b3d5 | 5R2/6R1/ 8/3b4/ p7/4R2P/ 2p3P1/ 6K1 w - - 0 59 | 0.001 | 0 | 0 |
|---|---|---|---|---|---|---|---|
| Field Explanation | Last State (FEN) | Action | Action History (maxlen 10) for repetitions | Observation (new State) | Reward (-1 loss or illegal, 0.5 draw, 1 win, 0.001 valid) | Termination (bool, True if game ends by WLD) | Truncation (bool, True if game ends by illegal action) |
| Inference | Prompt | Generated Environment Update |
Figure 3: arbiter-6m chess environment data representation. All fields concatenated into a string, delimited by “+”.
| Source Datasets & Splits | Combined Dataset | Combined Dataset Splits |
|---|---|---|
| rook-40m Valid (10k Samples) | - | - |
| rook-40m Train (40m Samples) | rookworld-46m | rookworld-46m Train (46m Samples) |
| arbiter-6m Train (6m Samples) | rookworld-46m Valid (15k Samples) | |
| arbiter-6m Valid (10k Samples) | - | - |
Table 1: Dataset composition
This environment model achieved promising results:
- 92% accuracy in generating correct observations on the validation set of arbiter-6m
- 99.8% normalized Levenshtein similarity on generated observations on the validation set of arbiter-6m
Encouraged by these results, we then trained a unified GPT-2 model using multi-task learning. This model, which we call RookWorld-LM, can perform both the policy task (deciding on moves) and the world-modeling task (simulating game outcomes) based on a prompt prefix. Interleaving the rook-40m and arbiter-6m datasets to rookworld-46m, we obtained 6.9 billion tokens for training RookWorld-LM.
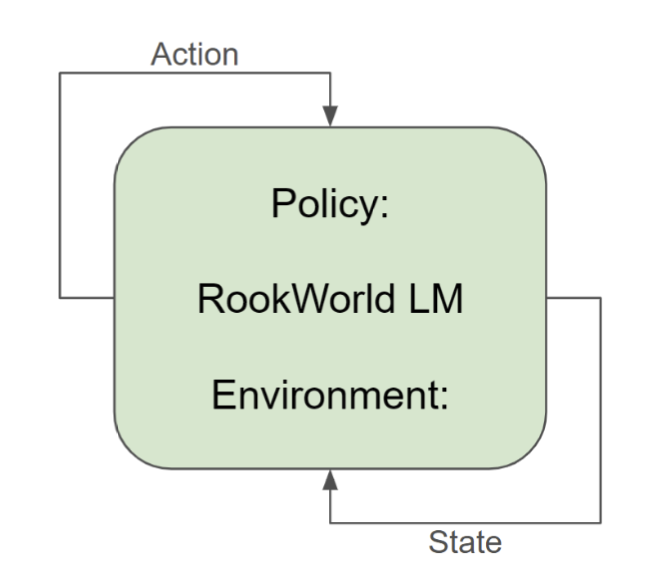
Figure 4: RookWorld-LM Self-Play Loop
The results of this unified model significantly improved upon the results of the separated models:
- 26.2% action accuracy on a validation split of the rook-40m dataset
- 32.1% accuracy on the Checkmate-in-One benchmark
- 99.9% accuracy on generated observations on the arbiter-6m validation set
Notably, RookWorld-LM's performance on the Checkmate-in-One benchmark surpasses that of ChessGPT-Base (Feng et al., 2023), a fine-tune of the Red Pajama 3b language model on a wide variety of chess-content, which achieved 26.5% accuracy.
RookWorld-LM represents, to our knowledge, one of the strongest chess policies without search implemented as an autoregressive decoder-transformer model to date. Its ability to self-play extended sequences of legal chess moves, combining policy decisions with environment simulation, opens up exciting new possibilities in AI research. You can try it yourself in this Colab Notebook and this Hugging Face Space.
5. Implications and Future Directions
The ROOK project has several significant implications for AI research:
- Strategic Reasoning: Our models confirm previous evidence (Li et al., 2023) that language models can learn complex strategic reasoning tasks without explicit coding of domain rules. This suggests potential applications far beyond chess, in areas requiring sophisticated decision-making and planning.
- World Modeling: RookWorld-LM's success in accurately simulating the chess environment points to the potential of language models in modeling complex, rule-based systems. This could lead to AI systems capable of reasoning about hypothetical scenarios and even judging the validity of their own outputs.
- Unified Architectures: The performance improvements seen in RookWorld-LM highlight the benefits of multi-task learning in creating versatile, multi-purpose AI systems. This approach could be extended to other domains, potentially leading to more general and capable AI systems.
As we release our research, including code, data, and evaluations, we invite collaboration from the community. Some promising directions for future research include:
- Scaling: Exploring the limits of language models for chess policies without search by scaling up model parameters, dataset size, and training duration. RookWorld-LM was trained on only 2x RTX 4090 GPUs and every increase in compute translated into improvements on benchmark performance (see Table 1). This could involve modifying the vocabulary of the GPT2-tokenizer to more efficiently capture chess-specific patterns.
- Self-Improvement: Investigating whether RookWorld-LM can improve its play through fine-tuning on filtered self-play games, keeping only the moves from winning games.
- Multi-Task Learning: Extending our multi-task approach to incorporate additional synthetically generated data from other strategic games or reasoning tasks (see Zhang et al., 2024).
- Transfer Learning: Exploring whether the strategic reasoning capabilities learned in the chess domain can transfer to language tasks or other problem-solving domains.
We're excited about the potential of this work and look forward to seeing how the AI research community builds upon and extends these ideas. The intersection of strategic games, language models, and reasoning systems remains a fertile ground for advancing our understanding of artificial intelligence.
Contributions:
Jonathan Rahn: led the project, designed experiments, executed experiments, developed the code bases, small scale dataset generation, analysis of results and writing
Qi Sun: co-design experiments and large scale dataset generation
Jenia Jitsev: scientific supervision and advising
Appendix
Open-source releases:
- Code:
- ROOK-CLF code (HF Transformers): jorahn/rook on GitHub
- ROOK-LM and RookWorld-LM code (LLM.c): jorahn/RookWorld on GitHub
- Datasets:
- ROOK-40m policy dataset: lfsm/rook-40m on Hugging Face Datasets
- Arbiter-6m environment dataset: jrahn/arbiter_6m on Hugging Face Datasets
- Trained Models:
- ROOK-CLF-9M trained model: jrahn/ROOK-CLF-9m on Hugging Face
- ROOK-LM-124M trained model: jrahn/ROOK-LM-124m on Hugging Face
- RookWorld-LM-124M trained model: jrahn/RookWorld-LM-124M on Hugging Face
- Inference Demos:
- Play RookWorld HF Space: jrahn/RookWorld on Hugging Face Spaces
- Inference ROOK-CLF, ROOK-LM, RookWorld-LM Colab: Colab Notebook
| Model | Dataset (Samples) | Steps (Epochs) | Action Accuracy | Checkmate in One Accuracy |
|---|---|---|---|---|
| ROOK-CLF (9M) | GDM 40M | 195,000 (5) | 49% | 57% |
| Ruoss et al., 2024 (9M, BC) | GDM 40M | ~55% | ||
| Ruoss er al., 2024 (270M, AV) | GDM 15.3B | 69.4% | ||
| ROOK-LM (124M) | ROOK 20k | 5,000 (2) | 0.6% | 0.0% |
| ROOK-LM (124M) | rook-260k | 18,752 (1) | 3.8% | 4.7% |
| ROOK-LM (124M) | rook-709k | 51,481 (1) | 7.4% | 4.8% |
| ROOK-LM (124M) | rook-709k | 102,962 (2) | 7.8% | 5.5% |
| ROOK-LM (124M) | rook-709k | 154,443 (3) | 8.8% | 7.0% |
| ROOK-LM (124M) | rook-5m | 11,646 (1) | 12.0% | 9.0% |
| ROOK-LM (124M) | rook-5m | 34,932 (3) | 13.4% | 11.5% |
| ROOK-LM (124M) | rook-40m | 278,154 (3) | 22.2% | 24.4% |
| RookWorld-LM (124M) | rookworld-7m | 47,203 (3) | 16.6% | 13.7% |
| RookWorld-LM (124M) | rookworld-46m | 529,400 (5) | 26.2% | 32.1% |
| Feng et al., 2023 ChessGPT-Base (3B, w/o suffix, MC) | 28.1M documents | 13.6% | ||
| Feng et al., 2023 ChessGPT-Base (3B, w/o suffix, ESM) | 28.1M documents | 26.5% |
Table 2: Results overview and dataset scaling
Related Work
Direct Inspirations:
- 2022 YoloChess - a Hugging Face Space by jrahn behavior cloning from human experts with DeBERTa v2
- 2023 Strategic Game Datasets for Enhancing AI Planning: An Invitation for Collaborative Research | LAION LAION & Qi Sun
- 2024 GitHub - karpathy/llm.c: LLM training in simple, raw C/CUDA
- 2024 Physics of Language Models - Part 2.1, Hidden Reasoning Process & [2407.20311] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process - CoT training data
Related Work:
- Chess-playing AI systems
- [1712.01815] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
- official-stockfish/Stockfish
- [2402.04494] Grandmaster-Level Chess Without Search
- A Very Unlikely Chess Game | Slate Star Codex
- [2306.09200] ChessGPT: Bridging Policy Learning and Language Modeling
- [2403.15498] Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models
- [2008.04057] The Chess Transformer: Mastering Play using Generative Language Models
- Language models in game environments
- [2406.06485] Can Language Models Serve as Text-Based World Simulators?
- [2402.08078] Large Language Models as Agents in Two-Player Games
- [2404.02039] A Survey on Large Language Model-Based Game Agents
- [2403.10249] A Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges
- World models and environment simulation
Public Code & Datasets
- Data generation
- Training
- Evaluation
- Datasets
- Models
- Space
- YouTube Presentation (23 mins) https://www.youtube.com/watch?v=5SkJQBrYY_g