OSSAS (OPEN SOURCE SUMMARIES AT SCALE) : THE INFERENCE.NET × LAION × GRASS
by: Christoph Schuhmann, Amarjot Singh, Andrii Prolorenzo, Andrej Radonjic, Sean Smith, and Sam Hogan, 11 Nov, 2025
Abstract
We present a comprehensive approach to democratizing access to scientific knowledge through large-scale, structured summarization of academic literature. We retrieved and processed ~100 million research papers from the public internet , leveraging existing datasets from bethgelab, PeS2o, Hugging Face, and Common Pile.
We designed a standardized JSON schema for scientific paper summaries and post-trained two models—Qwen 3 14B and Nemotron 12B—to produce summaries in this format. Our evaluation combines LLM-as-a-Judge and a QA dataset. Fine-tuned models achieve performance on our evals comparable to leading closed models (e.g., GPT-5, Claude 4.5). Nemotron 12B offers ~2.25× higher throughput than Qwen 3 14B, making it attractive for large-scale processing.
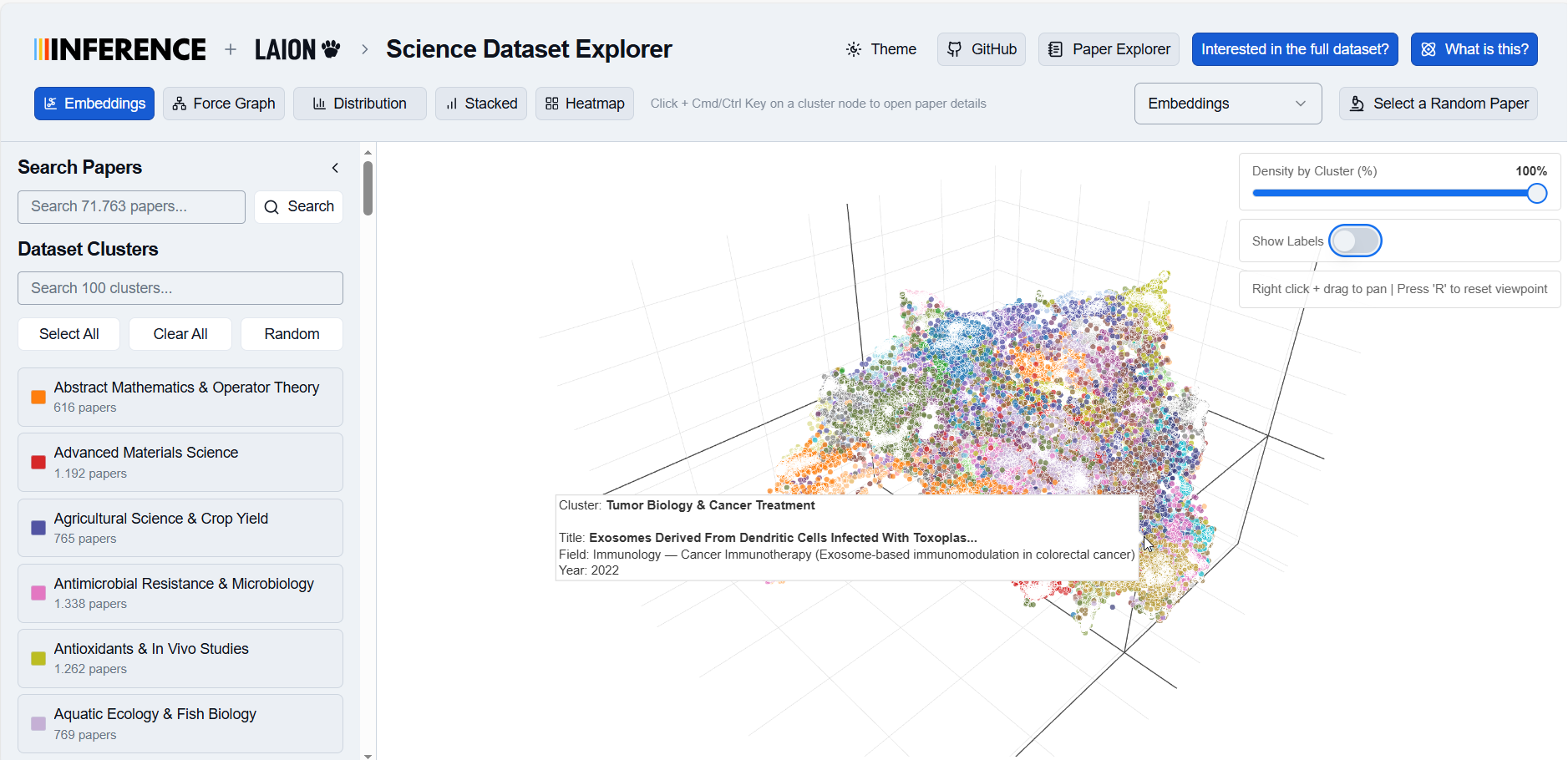
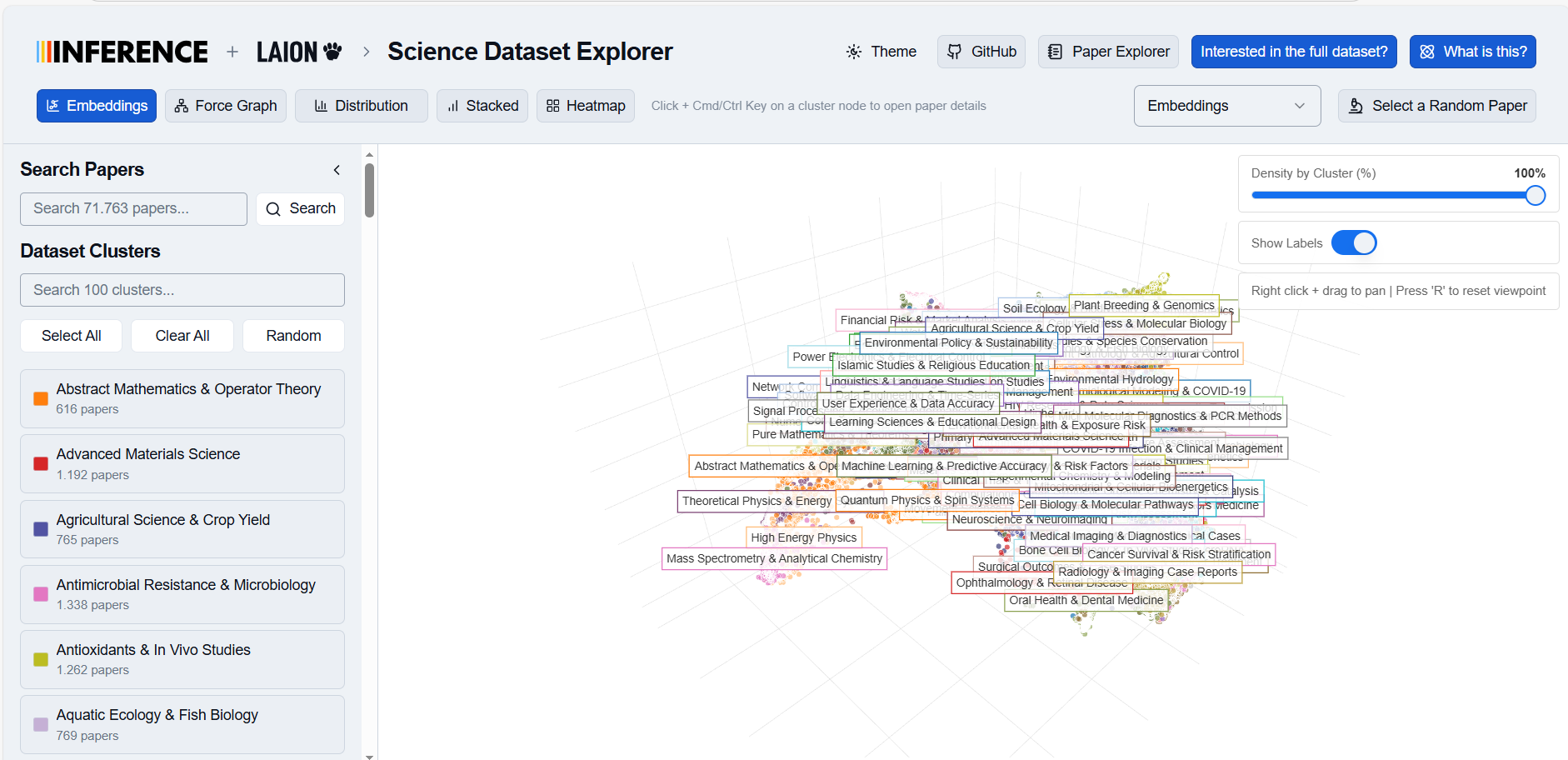
With this preliminary blog post, we release a fine-tuned models, 100k paper summaries. A live visualization tool at https://laion.inference.net/ demonstrates the utility of structured summaries. We plan to release structured summaries for the full 100M paper corpus.
Introduction
Access to scientific knowledge remains constrained by paywalls, licensing, and copyright, slowing research and education. Our Project Alexandria (arXiv:2502.19413) showed that it is legally and technically feasible to extract factual knowledge while respecting copyright via Knowledge Units—structured, style-agnostic representations of content. However, research-paper corpora vary in format and structure, making it hard to compare similar claims or retrieve knowledge efficiently. Building on Alexandria, we introduce a pipeline to collect, process, and summarize papers into structured outputs consumable by humans and AI systems alike. Our aims: * Create a massive, openly accessible, well-structured summary dataset of scientific literature * Develop models capable of generating structured, factual summaries * Demonstrate the utility of these summaries for scientific tasks * Explore decentralized computing to process at global scale This brief outlines methodology, results, and implications for the scientific community—and humanity.
Methodology
2.1 Dataset Collection & Processing
Primary corpus: ~100M research papers retrieved from the public internet through a collaboration with Grass. After deduplication, we supplemented with: * bethgelab: paper_parsed_jsons (dataset) *
LAION: COREX-18text (dataset) *
Common Pile: PubMed subset (dataset) *
LAION: PeS2oX-fulltext (dataset)
Post-training subset (110k papers): 40% from the retrieved corpus, 15% each from the four sources above. Split: 100k train / 10k val. Length stats: mean 81,334 characters, median 45,025 characters.
2.2 Structured Summary Schema
Inspired by Alexandria’s Knowledge Units, our JSON schema first classifies content: * SCIENTIFIC_TEXT — complete research articles * PARTIAL_SCIENTIFIC_TEXT — partial scientific content * NON_SCIENTIFIC_TEXT — non-research content For scientific texts, the schema extracts: title, authors, year, field/subfield, paper type, executive summary, research context, RQs & hypotheses, methods, procedures/architectures, key results (with numbers), interpretation, contradictions/limitations, claims (with supporting/contradicting evidence), data/code availability, robustness/ablations, ethics, key figures/tables, three takeaways. (See Appendix A.)
2.3 Model Post-Training
We post-trained: * Qwen 3 14B (dense Transformer) * Nemotron 12B (hybrid Mamba-Transformer) Targets were GPT-5-generated structured reports. A strict prompt guided classification, then schema-aligned extraction (executive summary, context, methods, procedures/architectures, key results, interpretations, contradictions, claims, data/code, robustness, ethics, key visuals, and three takeaways). See Appendix A for prompt.
2.4 Evaluation
We used two complementary approaches: 1. LLM-as-a-Judge — Ensemble of GPT-5, Gemini 2.5 Pro, and Claude 4.5 Sonnet, rating student outputs vs. GPT-5 references on a 1–5 rubric (accuracy, completeness, structure, clarity; hallucination checks). See survey [6]. 2. QA Dataset — For a holdout set, we generated 5 MCQs per paper with GPT-5 and measured models’ ability to answer using their own generated summaries (truncated to 10,000 chars), providing a proxy for factual utility (cf. Alexandria [1]).
Results
3.1 LLM-as-a-Judge
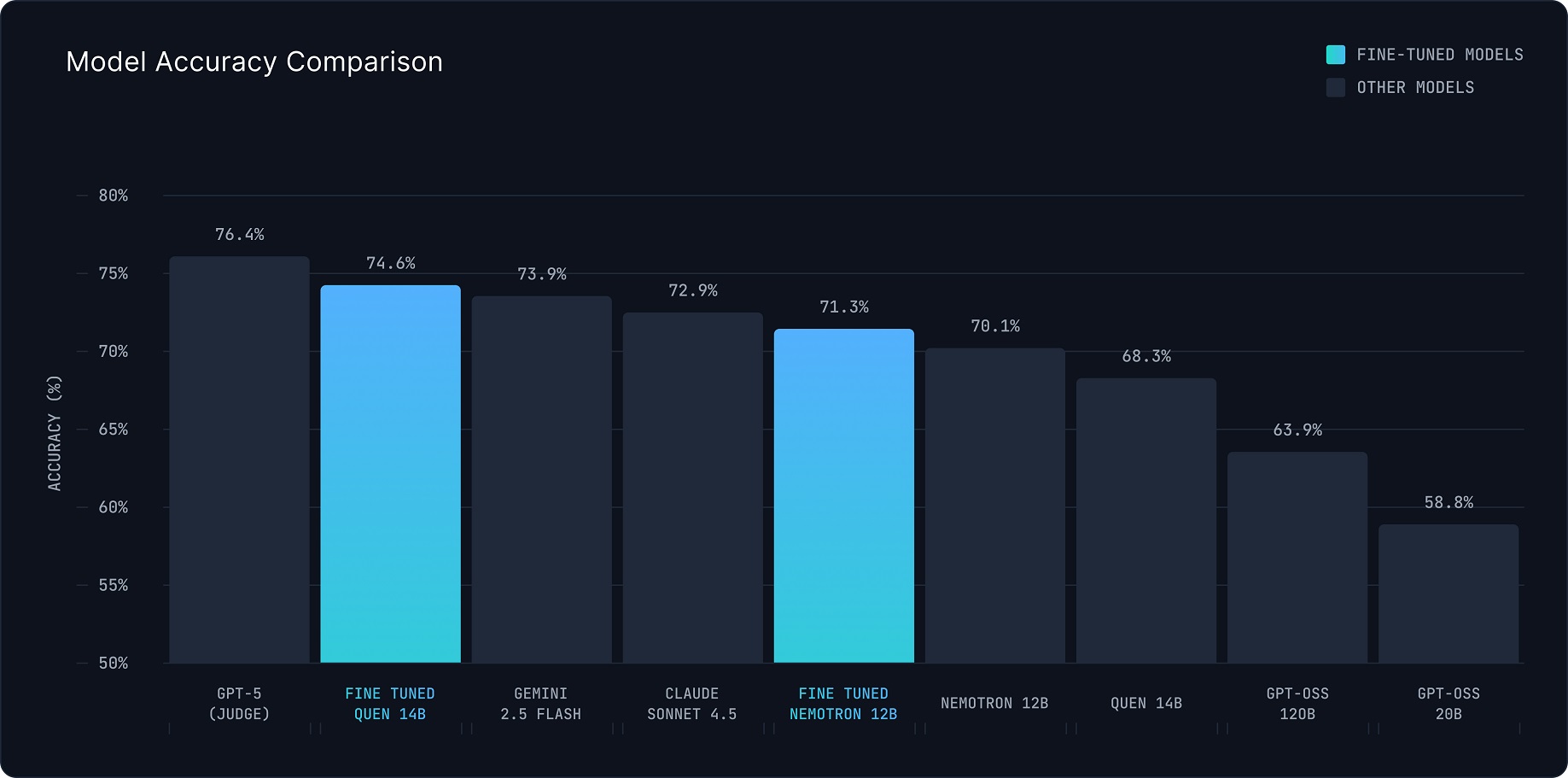
| Model | Score (1–5) |
|---|---|
| GPT-5 | 4.805 |
| Qwen 3 14B (FT) | 4.207 |
| Nemotron 12B (FT) | 4.095 |
| Gemini 2.5 Flash | 4.052 |
| Claude 4.5 Sonnet | 3.521 |
| GPT OSS 120B | 3.273 |
| Qwen 3 14B (Base) | 3.015 |
| GPT OSS 20B | 2.903 |
| Nemotron 12B (Base) | 2.179 |
Figure 1. Average LLM-as-a-Judge scores; 95% CIs via bootstrap.
3.2 QA Accuracy
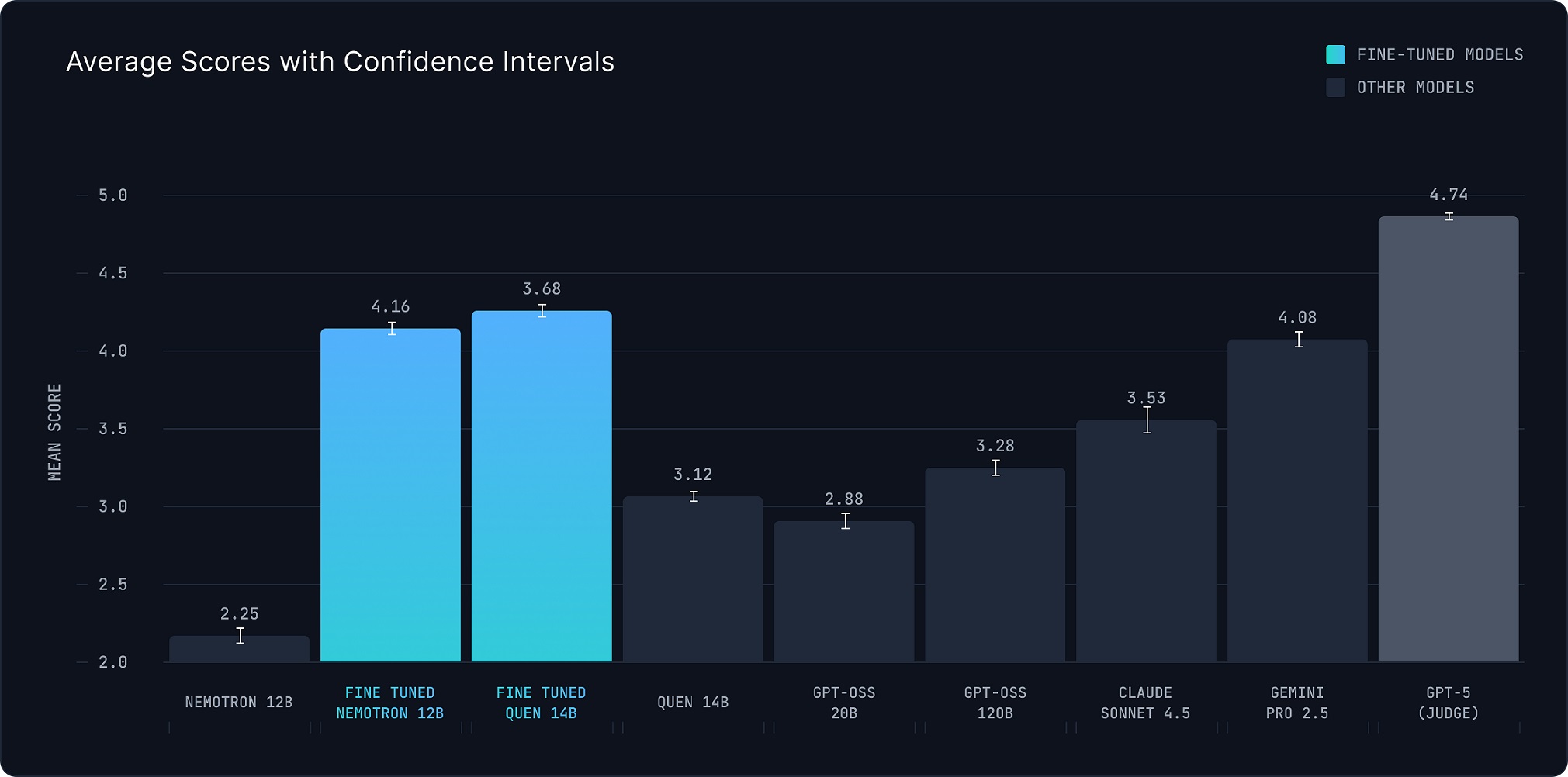
| Model | Accuracy (%) |
|---|---|
| GPT-5 | 74.6 |
| Qwen 3 14B (FT) | 73.9 |
| Gemini 2.5 Flash | 73.9 |
| Claude 4.5 Sonnet | 72.9 |
| Nemotron 12B (FT) | 71.3 |
| Nemotron 12B (Base) | 70.1 |
| Qwen 3 14B (Base) | 68.3 |
| GPT OSS 120B | 63.9 |
| GPT OSS 20B | 58.8 |
Figure 2. QA evaluation over 1,270 MCQs (multiple-choice accuracy).
3.3 Throughput on 8×H200 (TP=8, vLLM)
| Model | Requests/sec | Input tok/sec | Output tok/sec | Single-req tok/sec |
|---|---|---|---|---|
| Nemotron 12B | 0.97 | 16,943.69 | 4,880.76 | 76.17 |
| Qwen 3 14B | 0.43 | 7,516.54 | 2,588.30 | 39.59 |
Nemotron 12B delivers ~2.25× the throughput of Qwen 3 14B, favoring large-scale runs.
3.4 Visualization Tool
Explore 100k structured summaries (Qwen 3 14B FT outputs) at https://laion.inference.net/. We compute Qwen 3 Embedding 4B embeddings on summaries and use UMAP for clustering; cosine similarity supports nearest-neighbor exploration.
Discussion
4.1 Implications
Structured summaries enable:
- Faster retrieval across the literature
- Better machine reasoning on scientific content
- Improved accessibility where full texts are unavailable
- Novel visual analytics for mapping scientific landscapes
- Standardized English representations to simplify cross-domain search
Fine-tuned open models, correctly trained and formatted, are competitive for this task.
4.2 Decentralized Compute
Processing 100M papers is compute-intensive. The Inference.net permissionless GPU network (with verification) harnesses idle global compute at low cost, offering resilient infrastructure for science. Rough estimates: >$5M at current GPT-5 pricing vs. < $100k via decentralized nodes and our models.
4.3 Limitations
- Hallucinations remain possible, especially for fine-grained details (Ns, effect sizes, CIs, dates, units).
- LLM-as-a-Judge compresses multiple desiderata into one score; high scores don’t guarantee line-by-line fidelity.
- QA tests whether a smaller model can use a generated summary—not whether every atomic claim is exact.
- Context limits (e.g., 128k tokens) may force selective reading on very long papers.
- Domain heterogeneity can reduce recall in specialized subfields without further tuning.
- LLM-generated targets risk propagating upstream biases.
Appropriate use: Treat summaries as high-quality overviews for search/triage/review—not as substitutes for the source in high-stakes contexts. Verify numbers, dates, and terms in the original paper when precision is critical.
4.4 Outlook & Future Work
- Scale to 100M summaries + metadata: Join each summary to OpenAlex metadata (authors, venues, concepts, references, citations) for graph-native exploration at scale (https://docs.openalex.org/).
- Release permissive full texts + summaries: For permissively licensed papers (e.g., PeS2o, Common Pile PubMed), pair full text with structured summaries to support long-context training and grounded retrieval.
- From summaries to Knowledge Units: Iteratively convert summaries into Alexandria-style Knowledge Units (arXiv:2502.19413) to create a shareable factual substrate suited for open dissemination. (More compute-intensive; we will prioritize scaled summaries + metadata first.)
Conclusion
Open, large-scale structured summarization can significantly accelerate scientific discovery and education. Nemotron 12B provides superior throughput for at-scale processing; our fine-tuned models and released datasets show that open approaches can be both practical and competitive.
Our visualizer demonstrates real applications of structured summaries, and collaboration with Inference.net highlights how decentralized compute can tackle the processing challenges ahead.
Call to action:
We invite researchers, librarians, and open-access advocates to help us gather more papers for large-scale knowledge extraction. We also invite engineers and compute providers to help optimize our paragraph-level pipeline and contribute GPU capacity (decentralized nodes, clusters, credits) so we can run inference over the full corpus and convert it into Alexandria-style Knowledge Units—freeing factual scientific knowledge for education and accelerated research.
Acknowledgments
This is a collaboration between LAION, Grass and Inference.net. We thank all contributors, especially Tawsif Ratul for data collection, and Prof. Sören Auer, Dr. Gollam Rabby, and the TIB – Leibniz Information Centre for Science and Technology for scientific advice and support.
References
- Alexandria Project (2023). Democratizing access to scientific knowledge. https://projects.laion.ai/project-alexandria/
- bethgelab Paper Dataset (2024). https://huggingface.co/datasets/bethgelab/paper_parsed_jsons
- LAION COREX-18text (2024). https://huggingface.co/datasets/laion/COREX-18text
- Common Pile PubMed (2024). https://huggingface.co/datasets/common-pile/pubmed
- LAION PeS2oX-fulltext (2024). https://huggingface.co/datasets/laion/Pes2oX-fulltext
- A Survey on LLM-as-a-Judge (2025). https://arxiv.org/abs/2411.15594
- Inference.net Paper Visualizer (2025). https://laion.inference.net/
- Qwen 3 Embedding 4B (2025). https://huggingface.co/Qwen/Qwen3-Embedding-4B
Appendix A — Implementation Details
A.1 LLM-as-a-Judge Prompt
You are an expert judge evaluating the quality of AI-generated summarizations of scientific research articles. Your task is to evaluate how well a student model's response compares to a teacher model's response (considered the ground truth).
Evaluation Rubric (1-5 scale)
Score 5 - Excellent:
- Matches or exceeds the teacher response in accuracy and completeness
- All key information is present and correctly extracted
- Structure and formatting are clear and well-organized
- No hallucinations or incorrect information
- Demonstrates deep understanding of the scientific content
Score 4 - Good:
- Very similar to teacher response with only minor omissions
- All critical information is captured correctly
- May have slight differences in phrasing or organization
- No significant errors or hallucinations
- Demonstrates good understanding of the scientific content
Score 3 - Average:
- Captures main ideas but missing some important details
- Generally accurate but may have minor inaccuracies
- Structure may be less clear than teacher response
- May have minor inconsistencies
- Demonstrates basic understanding but lacks depth in places
Score 2 - Below Average:
- Missing significant portions of key information
- Contains notable inaccuracies or errors
- Poor structure or organization
- May have some hallucinations or incorrect extrapolations
- Demonstrates limited understanding of the scientific content
Score 1 - Poor:
- Fundamentally incorrect or irrelevant
- Major hallucinations or fabricated information
- Missing most critical information
- Incomprehensible or poorly structured
- Demonstrates little to no understanding of the scientific content
Instructions:
1. Compare the student response against the teacher response
2. Consider the original input as context for what was asked
3. Evaluate accuracy, completeness, structure, and clarity
4. Look for hallucinations or incorrect information
5. Provide specific comments on strengths and weaknesses
Output Format (JSON):
{
"score": <integer 1-5>,
"comments": "<detailed explanation of your evaluation>"
}
A.2 JSON Schema (Article Response)
{
"name": "article_response",
"schema": {
"$defs": {
"ArticleClassification": {
"description": "Classification of the article content.",
"enum": ["SCIENTIFIC_TEXT", "PARTIAL_SCIENTIFIC_TEXT", "NON_SCIENTIFIC_TEXT"],
"title": "ArticleClassification",
"type": "string"
},
"Claim": {
"description": "Individual research claim with supporting evidence.",
"properties": {
"details": {
"description": "Testable claim details grounded in specific reported numbers/figures/tables",
"title": "Details",
"type": "string"
},
"supporting_evidence": {
"description": "Evidence that supports this claim from the paper",
"title": "Supporting Evidence",
"type": "string"
},
"contradicting_evidence": {
"description": "Evidence that contradicts or limits this claim, or empty string if none",
"title": "Contradicting Evidence",
"type": "string"
},
"implications": {
"description": "Implications of this claim for the broader field",
"title": "Implications",
"type": "string"
}
},
"required": ["details", "supporting_evidence", "contradicting_evidence", "implications"],
"title": "Claim",
"type": "object",
"additionalProperties": false
},
"ScientificSummary": {
"description": "Complete structured summary of a scientific paper.",
"properties": {
"title": { "description": "Exact paper title as it appears in the original paper", "title": "Title", "type": "string" },
"authors": { "description": "Full list of authors in publication order, including affiliations if provided", "title": "Authors", "type": "string" },
"publication_year": {
"anyOf": [{ "type": "integer" }, { "type": "null" }],
"default": null,
"description": "Publication year of the paper if available, must be a valid integer",
"title": "Publication Year"
},
"field_subfield": { "description": "Academic field and subfield, e.g. 'Computer Science — Vision'", "title": "Field Subfield", "type": "string" },
"type_of_paper": { "description": "Type: theoretical, empirical, methodological, implementation, review, etc.", "title": "Type Of Paper", "type": "string" },
"executive_summary": { "description": "Concise narrative: problem, what was done, key findings (with numbers), novelty, significance, limitations", "title": "Executive Summary", "type": "string" },
"research_context": { "description": "Background gap/controversy, closest prior work, what this addresses", "title": "Research Context", "type": "string" },
"research_question_and_hypothesis": { "description": "Central research questions, explicit hypotheses/predictions and alternatives", "title": "Research Question And Hypothesis", "type": "string" },
"methodological_details": { "description": "Design, participants/sample, materials/data, procedure, analysis", "title": "Methodological Details", "type": "string" },
"procedures_and_architectures": { "description": "Models/systems/apparatus, architectures, hyperparameters, what's new", "title": "Procedures And Architectures", "type": "string" },
"key_results": { "description": "Quantitative/qualitative findings with actual numbers; baseline/SOTA comparisons; robustness", "title": "Key Results", "type": "string" },
"interpretation_and_theoretical_implications": { "description": "What findings mean for RQs and theory; mechanisms; scope", "title": "Interpretation And Theoretical Implications", "type": "string" },
"contradictions_and_limitations": { "description": "Inconsistencies, methodological constraints, external validity, conflicts with prior literature", "title": "Contradictions And Limitations", "type": "string" },
"claims": { "description": "List of testable claims grounded in specific reported numbers/figures/tables", "items": { "$ref": "#/$defs/Claim" }, "title": "Claims", "type": "array" },
"data_and_code_availability": { "description": "Links, licenses, prereg, supplements, or empty string", "title": "Data And Code Availability", "type": "string" },
"robustness_and_ablation_notes": { "description": "Ablations/sensitivity/stability analysis, or empty string", "title": "Robustness And Ablation Notes", "type": "string" },
"ethical_considerations": { "description": "Risks, mitigations, approvals, privacy/consent, dual use, or empty string", "title": "Ethical Considerations", "type": "string" },
"key_figures_tables": { "description": "Critical figures/tables, what they show, and how they substantiate claims", "title": "Key Figures Tables", "type": "string" },
"three_takeaways": { "description": "Three short paragraphs: (1) core novelty, (2) strongest evidence with numbers, (3) primary limitation", "title": "Three Takeaways", "type": "string" }
},
"required": ["title", "authors", "publication_year", "field_subfield", "type_of_paper", "executive_summary", "research_context", "research_question_and_hypothesis", "methodological_details", "procedures_and_architectures", "key_results", "interpretation_and_theoretical_implications", "contradictions_and_limitations", "claims", "data_and_code_availability", "robustness_and_ablation_notes", "ethical_considerations", "key_figures_tables", "three_takeaways"],
"title": "ScientificSummary",
"type": "object",
"additionalProperties": false
}
},
"description": "Top-level response structure for article processing.",
"properties": {
"article_classification": { "$ref": "#/$defs/ArticleClassification" },
"reason": {
"anyOf": [{ "type": "string" }, { "type": "null" }],
"default": null,
"description": "Reason when classification is NON_SCIENTIFIC_TEXT",
"title": "Reason"
},
"summary": {
"anyOf": [{ "$ref": "#/$defs/ScientificSummary" }, { "type": "null" }],
"default": null,
"description": "Scientific summary if article is SCIENTIFIC_TEXT or PARTIAL_SCIENTIFIC_TEXT"
}
},
"required": ["article_classification", "reason", "summary"],
"title": "ArticleResponse",
"type": "object",
"additionalProperties": false
}
}